사용자가 에이전트와 30분간의 세션을 마칩니다. 사용자는 요구 사항을 공유하고, 선호도를 밝히고, 결정을 내렸습니다. 하지만 새로운 세션을 시작하면 그 어떤 내용도 유지되지 않습니다. 보통 문제가 되는 것은 에이전트의 추론 능력이 아니라 AI 에이전트 메모리 통합(memory consolidation)입니다. 이는 원시 대화 기록을 구조화된 장기 기억으로 변환하는 백그라운드 단계입니다. 이 단계는 단일 모델에 대한 단일 API 호출로 이루어지는데, 단일 API 호출은 실패하기 마련입니다. 속도 제한(Rate limits), 타임아웃, 잘못된 도구 출력 등은 모두 동일한 증상을 유발합니다. 바로 사용자에게 오류가 표시되지 않는 조용한 메모리 손실입니다.
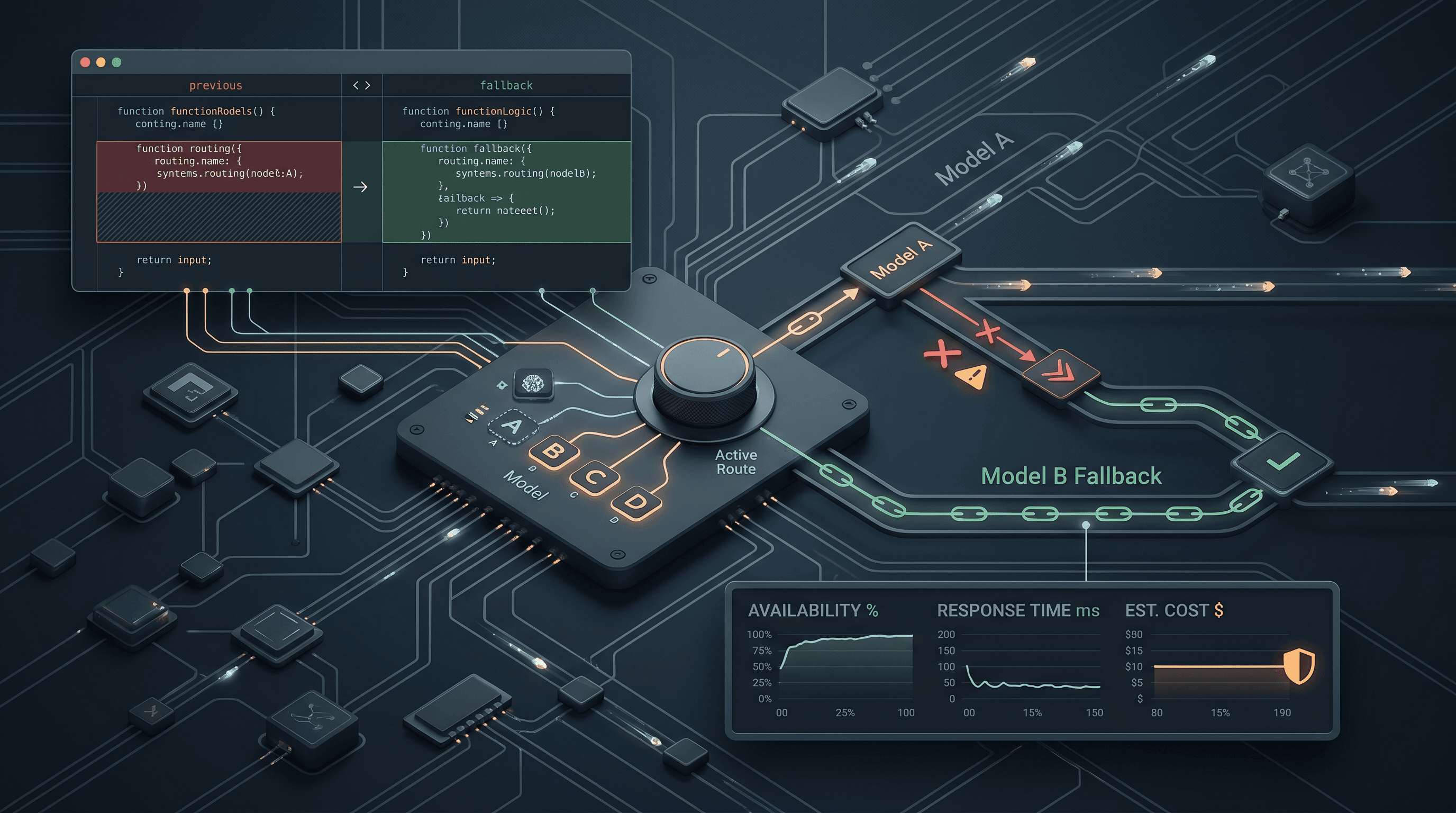
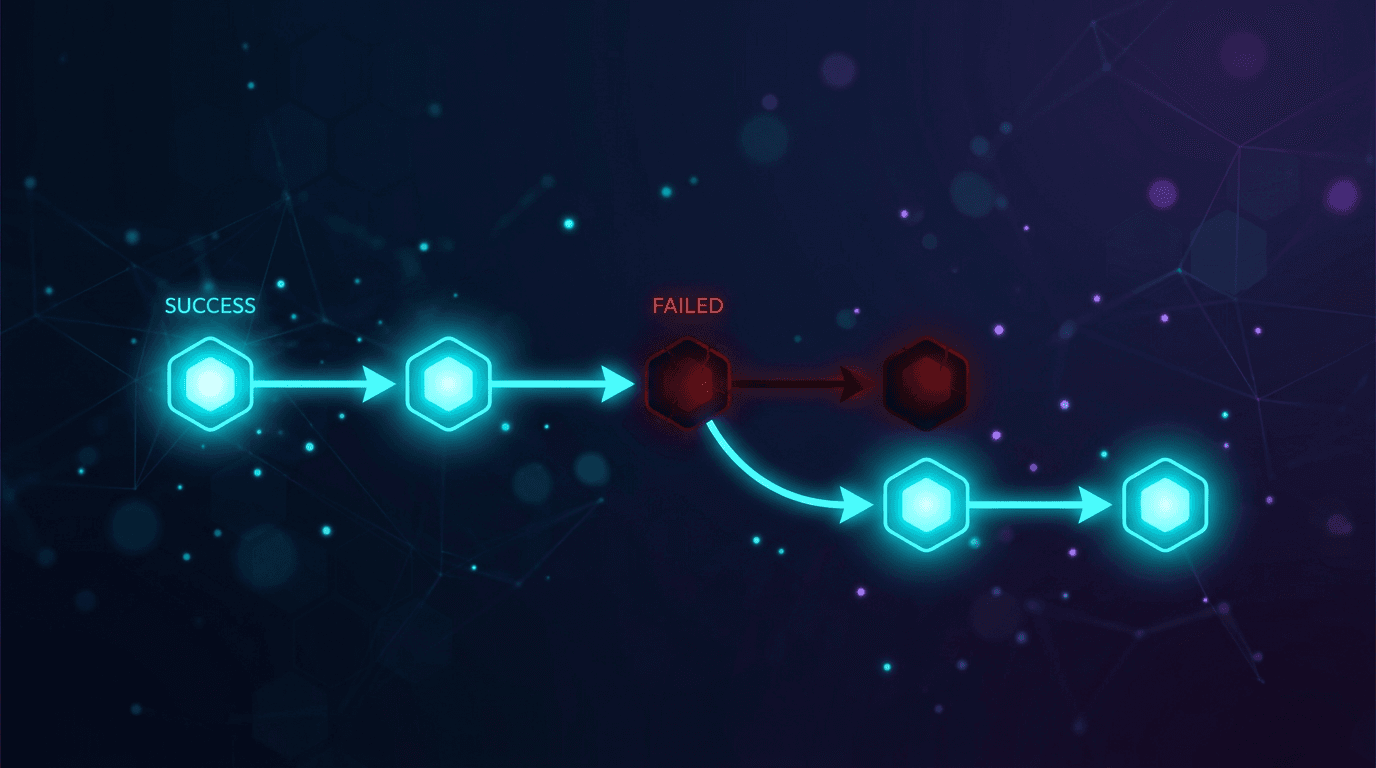
이 글에서 제시하는 해결책은 더 나은 프롬프트가 아닌 아키텍처적 접근입니다. 하나의 모델 대신 모델의 순차적 체인(ordered chain)을 통해 통합을 실행하여, 특정 제공업체에서 오류가 발생하더라도 대화 내용이 삭제되지 않도록 하는 것입니다.
메모리 하위 시스템뿐만 아니라 주변 제품 인터페이스를 구축 중이라면, 이 페이지와 함께 원키 챗봇 가이드 및 AI API 속도 제한 가이드를 참고하세요. 개별 모델이 아닌 제공업체를 비교 중이라면 이 글과 함께 OpenRouter 비교 문서를 읽어보시기 바랍니다.
핵심 요약
- 메모리 통합은 좁고 구조화된 출력 작업(도구 호출 또는 강제 JSON)이며, 구조화된 출력 호출은 자유 형식의 채팅보다 스키마 위반, 잘림(truncation), 속도 제한, 타임아웃 등 더 많은 실패 모드를 가집니다.
- 통합을 처리하는 단일 모델은 단일 실패 지점(single point of failure)입니다. 통합을 프롬프트 엔지니어링 문제가 아닌, 폴백 체인(fallback chain)을 갖춘 신뢰성 문제로 다루십시오.
- 2계층 체인이 실무에서 효과적입니다. 1계층은 저비용 모델(DeepSeek V4 Flash, GLM-5.2, Qwen3.7 Plus, Gemini 3.5 Flash, GPT-5.5)의 시퀀스로, 오류 발생 시 서로 페일오버(failover)합니다. 2계층은 모든 1계층 모델이 실패했을 때만 Claude Sonnet 5, 이후 Claude Opus 4.8로 에스컬레이션합니다.
- 이 글은 이 특정 런타임에 대해 공개되고 재현 가능한 실패율이나 비용 절감 비율을 제시하지 않습니다. 아래의 가격 산정은 예시일 뿐입니다. 수치를 인용하기 전에 자신의 워크로드를 직접 측정하십시오.
- 이 체인은 하나의 제공업체를 반복적으로 재시도하는 대신 독립적인 제공업체 간에 페일오버하므로 특정 속도 제한에 부하가 집중되지 않으며, 통합이 비동기 백그라운드 작업으로 실행되므로 재시도 지연 시간이 사용자 대화 흐름을 차단하지 않습니다.
AI 에이전트 메모리 통합이란 무엇인가?
메모리 통합은 원시 대화 기록을 사용자 선호도, 결정, 프로젝트 상태, 언급된 엔티티와 같은 구조화되고 지속 가능한 사실로 변환하는 과정입니다. 이는 현재 세션의 메시지를 보관하는 에이전트의 활성 컨텍스트 창과는 다릅니다. 통합은 일반적으로 세션당 한 번(종료 시, 유휴 타임아웃 시, 또는 롤링 윈도우 시) 실행되며, 채팅창이 아닌 데이터베이스, 벡터 저장소 또는 메모리 서비스에 출력을 기록합니다.
출력이 스키마와 일치해야 하므로(하위 검색 코드가 사용할 수 있도록), 통합은 거의 항상 일반적인 채팅 응답이 아닌 강제 도구 호출이나 JSON 모드 완료로 구현됩니다. 바로 이 점이 시스템을 취약하게 만듭니다. 모델이 대화는 잘 수행하더라도 도구 호출 대신 산문을 반환하거나, 긴 기록에서 JSON을 잘라내거나, 스키마에 없는 필드를 생성하여 통합 단계에서 실패할 수 있기 때문입니다.
단일 모델 통합이 실패하는 이유
구조화된 출력 호출은 일반 채팅 완료보다 더 많은 실패 모드를 가집니다:
- 모델이 도구 스키마를 무시하고 도구 호출 대신 산문을 반환합니다.
- 트래픽 급증 시 제공업체가 속도 제한(429) 또는 서버 오류(500/502/503)를 반환합니다.
- 요청이 타임아웃됩니다. 특히 요약에 더 많은 토큰이 필요한 긴 기록에서 자주 발생합니다.
- 모델이 스키마와 일치하지 않는 필드 이름이나 유형을 포함한 유효한 JSON을 반환합니다.
이 중 하나라도 발생하면 완료된 대화가 조용한 메모리 공백으로 변합니다. 사용자에게는 오류가 표시되지 않습니다. 나중에 에이전트가 무언가를 "잊어버렸을 때" 사용자는 이를 알아차리게 되며, 그때는 원시 기록을 별도로 보관하지 않았다면 이미 사라진 상태일 것입니다.
이 특정 런타임, 워크로드 또는 날짜에 대한 제어된 실패율 벤치마크를 게시하지 않았으므로, 여기서 특정 비율을 다시 언급하지는 않겠습니다. 검증 가능한 것은 메커니즘입니다. 위에서 언급한 네 가지 구체적인 실패 모드는 모델을 체인으로 연결하면 단일 실패 지점으로서의 위험이 제거됩니다.
폴백 체인을 위한 모델 가격
아래 표는 이 글에서 설명하는 폴백 체인에 사용된 모델들의 현재 TokenLab 가격을 나열합니다. 이는 TokenLab의 실시간 가격 스냅샷이며, 제공업체가 게시한 문서와는 다를 수 있습니다. 토큰당 가격은 시간이 지남에 따라 변경되므로 주문을 확정하기 전에 확인하십시오.
| 모델 | 컨텍스트 창 | 입력 $/MTok | 출력 $/MTok | 출처 | 관측일 |
|---|---|---|---|---|---|
| DeepSeek V4 Flash | 1,048,576 | $0.09 | $0.18 | TokenLab 실시간 모델/가격 스냅샷 | 2026-07-09 |
| GLM-5.2 | 1,048,576 | $0.93 | $3.00 | TokenLab 실시간 모델/가격 스냅샷 | 2026-07-09 |
| Qwen3.7 Plus | 1,000,000 | $0.32 | $1.28 | TokenLab 실시간 모델/가격 스냅샷 | 2026-07-09 |
| Gemini 3.5 Flash | 1,048,576 | $1.50 | $9.00 | TokenLab 실시간 모델/가격 스냅샷 | 2026-07-09 |
| GPT-5.5 | 1,050,000 | $5.00 | $30.00 | TokenLab 실시간 모델/가격 스냅샷 | 2026-07-09 |
| Claude Sonnet 5 | 1,000,000 | $2.00 | $10.00 | TokenLab 실시간 모델/가격 스냅샷 | 2026-07-09 |
| Claude Opus 4.8 | 1,000,000 | $5.00 | $25.00 | TokenLab 실시간 모델/가격 스냅샷 | 2026-07-09 |
실시간 속도 제한, 최신 가격 및 신뢰성 순위는 체인 순서를 확정하기 전에 TokenLab 모델 디렉토리와 모델 리더보드를 확인하십시오.
프로덕션 환경에서 메모리 통합 트래픽을 라우팅하는 경우, TokenLab을 시작하여 제공업체별 자격 증명, 속도 제한 및 오류 형식을 관리하는 대신 단일 API 키로 이 7개 모델 모두에 액세스하십시오.
이중 계층 폴백 아키텍처
1계층: 저비용, 대용량, 제공업체 다양성
이 계층은 모든 통합 이벤트에서 실행됩니다. 최소 3개 이상의 서로 다른 제공업체에 걸쳐 다음 순서로 모델을 체인으로 연결하십시오:
- DeepSeek V4 Flash
- GLM-5.2
- Qwen3.7 Plus
- Gemini 3.5 Flash
- GPT-5.5
도구 호출 실패, 스키마 위반, 타임아웃 또는 4xx/5xx 응답이 발생하면 즉시 목록의 다음 모델로 이동하십시오. 1계층에서 동일한 모델을 재시도하지 마십시오. 속도 제한이나 잘못된 응답은 즉각적인 재시도 시 해결될 가능성보다 반복될 가능성이 더 높습니다.
2계층: 실제 엣지 케이스를 위한 에스컬레이션
모든 1계층 모델이 실패하면 1계층을 다시 반복하는 대신 더 강력한 모델로 에스컬레이션하십시오:
- Claude Sonnet 5
- Claude Opus 4.8 (최종 폴백)
2계층은 드물게 사용되어야 합니다. 로그에서 2계층 에스컬레이션이 자주 발생한다면, 이는 2계층을 기본 경로로 만들 이유가 아니라 1계층 순서, 스키마 엄격성 또는 기록 길이를 점검해야 한다는 신호입니다.
비동기 백그라운드 메모리 통합 구현 방법
통합은 사용자의 다음 메시지를 절대 차단해서는 안 됩니다. 세션 종료 또는 유휴 타임아웃 시 트리거되는 백그라운드 작업으로 실행하고, 채팅 응답 경로에 포함하지 말고 완료 시 메모리 저장소에 기록하십시오. 이러한 분리는 다중 모델 체인의 최악의 지연 시간을 허용 가능한 수준으로 만드는 요소이기도 합니다. 백그라운드 작업자에서 몇 초간의 추가 재시도는 사용자 대화에 아무런 영향을 주지 않습니다.
코드를 제외한 제어 흐름은 다음과 같습니다:
- 세션 종료 또는 유휴 타임아웃 시 전체 기록을 포함한 백그라운드 작업을 대기열에 넣습니다.
- 작업자는 시도당 제한된 타임아웃을 설정하여 1계층 목록의 첫 번째 모델에 대해 통합을 시도합니다.
- 타임아웃, 429 또는 5xx 발생 시 작업자는 동일한 모델에 대한 현장 재시도 없이 즉시 목록의 다음 모델로 이동합니다.
- 200 응답 시 작업자는 페이로드를 수락하기 전에 JSON 스키마에 대해 유효성을 검사합니다. HTTP 상태 확인은 통과했지만 스키마 유효성 검사에 실패한 응답은 네트워크 실패와 동일하게 처리합니다(로그 기록 후 다음 모델로 이동).
- 모든 1계층 모델이 실패하면 작업자는 동일한 타임아웃 및 유효성 검사 로직을 사용하여 2계층(Claude Sonnet 5, 이후 Claude Opus 4.8)으로 에스컬레이션합니다.
- 두 계층의 모든 모델이 실패하면 작업자는 통합되지 않은 원시 기록을 저장소에 보관하고 온콜 엔지니어에게 알립니다. 통합 해결 방식과 관계없이 원시 기록은 절대 삭제되지 않습니다.
- 각 이벤트를 해결한 모델(또는 전체 체인 실패 여부)을 기록하여 1계층 해결률을 측정하고 나중에 체인 순서를 재조정할 수 있도록 합니다.
이 7개 제공업체에 대한 특정 SDK 메서드 이름, 요청 페이로드 또는 응답 형태가 포함된 복사 가능한 코드 샘플은 게시하지 않습니다. 이 증거 세트에는 각 항목에 대한 검증된 엔드포인트, 인증 및 페이로드 세부 정보가 포함되어 있지 않으며, 이를 임의로 작성하면 올바르게 보이지만 프로덕션에서 조용히 실패하는 통합 코드가 생성될 수 있기 때문입니다. 이 흐름을 구현하기 전에 각 제공업체의 자체 문서에 대해 아래의 검증 체크리스트를 확인하십시오.
구현 전 검증 체크리스트
- 각 제공업체의 구조화된 출력 또는 도구 호출 모드에 대한 현재 엔드포인트, 인증 헤더 형식 및 요청 본문 형태를 타사 요약이 아닌 공식 API 참조에서 직접 확인하십시오.
- 각 제공업체의 SDK가 429, 500/502/503 및 클라이언트 측 타임아웃에 대해 발생시키는 예외 또는 오류 객체를 확인하십시오. 이는 SDK마다 다르며 SDK 버전에 따라 변경됩니다.
- 각 제공업체의 클라이언트 라이브러리에 비활성화해야 할 내장 재시도 메커니즘이 있는지 확인하십시오. 라이브러리 내 재시도가 아닌 교차 제공업체 페일오버를 원하기 때문입니다.
- JSON 스키마 유효성 검사기가 HTTP 200을 반환하는 응답을 포함하여
persist_memory에 도달하기 전 모든 응답에 대해 실행되는지 확인하십시오. - 각 제공업체를 직접 호출하는 대신 TokenLab과 같은 다중 제공업체 게이트웨이를 통해 라우팅하는 경우, 제공업체별 오류 코드가 변경 없이 전파된다고 가정하기 전에 tokenlab.sh/en/models 문서에서 게이트웨이 자체의 오류 전달 형식을 확인하십시오.
실제 실패 클래스에 매핑된 오류 처리 참고 사항
| 오류 클래스 | 처리 방법 |
|---|---|
| 429 속도 제한 | 즉시 다음 모델로 이동하십시오. 루프 내에서 동일한 모델을 재시도하지 마십시오. 한 모델이 반복적으로 속도 제한을 걸면 향후 호출에서 다시 시도하기 전에 짧은 쿨다운을 추가하십시오. |
| 500/502/503 서버 오류 | 일시적인 것으로 간주하십시오. 다음 모델로 이동하십시오. 이 체인 내에 지수 백오프(exponential backoff)를 추가하지 마십시오. 다른 제공업체로 페일오버하는 것이 한 제공업체의 중단을 기다리는 것보다 빠릅니다. |
| 타임아웃 | 각 시도에 제한을 두십시오(호출당 5-10초의 예시 제한; 기록 길이에 맞게 조정). 타임아웃 시 대기 시간을 연장하는 대신 다음 모델로 이동하십시오. |
| 429 이외의 4xx | 보통 사용자의 요청 형식 버그입니다. 크게 로그를 남기고 담당자에게 알리십시오. 가시성 없이 영원히 조용히 페일오버되도록 두지 마십시오. |
| 잘못된 본문을 포함한 200 OK | 수락하기 전에 JSON 스키마에 대해 유효성을 검사하십시오. 구문상 유효하지만 형태가 잘못된 응답은 여전히 실패이며, HTTP 상태뿐만 아니라 유효성 검사로 포착해야 합니다. |
"이것이 속도 제한 고갈을 유발하지 않는가"라는 반론에 대해: 각 1계층 모델은 서로 다른 제공업체 뒤에 있으므로 하나에서 발생한 429가 다른 제공업체의 할당량을 소모하지 않습니다. 체인은 부하를 집중시키는 대신 분산시킵니다. 최악의 경우 5번의 1계층 시도와 2번의 2계층 시도로 총 7번의 호출이 발생합니다. 시도당 8초의 타임아웃 제한을 두면 최악의 경우 약 1분으로 제한됩니다. 이 시나리오는 모든 제공업체가 동시에 실패해야 발생하며, 이는 이 설계가 생존하도록 구축된 드문 엣지 케이스이지 일반적인 경로가 아닙니다. 이는 구성한 타임아웃에 기반한 제한이며 측정된 프로덕션 지연 시간 벤치마크가 아닙니다. 이 체인을 부하 상태에서 실행하지 않았으며 측정된 p50/p99를 보고하지 않습니다.
폴백 체인 전반의 예시 비용 비교
대부분의 볼륨을 저렴한 모델로 라우팅하는 것이 중요한 이유를 보여주기 위해 위의 가격표를 사용한 작업 예시를 제시합니다. 가정: 평균 통합 호출은 입력으로 3,000토큰의 기록을 보내고 400토큰의 구조화된 출력을 생성합니다. 이는 특정 고객 워크로드에서 측정된 평균이 아닌 예시적인 가정입니다. 자신의 토큰 수를 대입하십시오.
| 모델 | 호출당 비용 (위의 가정) |
|---|---|
| DeepSeek V4 Flash | $0.00034 |
| Qwen3.7 Plus | $0.00147 |
| GLM-5.2 | $0.00399 |
| Gemini 3.5 Flash | $0.00810 |
| Claude Sonnet 5 | $0.01000 |
| Claude Opus 4.8 | $0.02500 |
| GPT-5.5 | $0.02700 |
차이는 실재합니다. 이 가정하에 100%의 호출을 GPT-5.5로 라우팅하는 것은 DeepSeek V4 Flash로 라우팅하는 것보다 호출당 약 80배 더 많은 비용이 듭니다. 자체 데이터 없이는 트래픽의 몇 퍼센트가 실제로 1계층에서 해결되고 몇 퍼센트가 2계층으로 에스컬레이션되는지 알 수 없습니다. 이는 기록 길이, 스키마 복잡성 및 실행 당일의 제공업체 신뢰성에 따라 달라지기 때문입니다. 각 이벤트를 해결하는 모델을 기록하고(위 구현 흐름의 7단계), 빌려온 비율에 의존하는 대신 몇 천 건의 이벤트 후 자체 혼합 비용을 계산하십시오.
제한 사항
- 이 증거 세트에는 이 특정 체인, 워크로드 또는 날짜에 대한 공개되고 재현 가능한 실패율 벤치마크가 존재하지 않습니다. 특정 수치를 인용하기 전에 자체 런타임에서 로깅을 계측하십시오.
- 위의 비용 표는 측정된 평균 기록 길이가 아닌 가정된 토큰 수를 사용합니다. 가격표의 출처와 관측일을 사용하여 자신의 수치로 다시 계산하십시오.
- 모델 가격과 컨텍스트 창은 변경됩니다. 프로덕션을 위한 체인 순서를 확정하기 전에 TokenLab 모델 디렉토리에서 현재 값을 확인하십시오.
- 폴백 체인은 단일 실패 지점 위험을 줄이지만 데이터 손실 제로를 보장하지는 않습니다. 항상 원시 기록을 구조화된 통합 출력과 별도로 보관하십시오.
- 이 글의 지연 시간 및 속도 제한 고갈 수치는 구성 가능한 타임아웃에 기반한 추정치이며 측정된 프로덕션 벤치마크가 아닙니다. 이 증거 세트에서 이 체인을 부하 상태로 실행하지 않았습니다.
- 이 글에는 의도적으로 복사 가능한 요청 코드가 포함되어 있지 않습니다. 작성 시점에 이 7개 제공업체에 대한 정확한 엔드포인트, 인증 헤더 및 페이로드 증거를 확인할 수 없었기 때문입니다. 구현하기 전에 검증 체크리스트와 각 제공업체의 공식 문서를 사용하십시오.
구현 체크리스트
| 관행 | 중요한 이유 |
|---|---|
| HTTP 상태뿐만 아니라 스키마 검증 | 잘못된 JSON이나 누락된 도구 호출이 포함된 200 응답은 여전히 재시도 로직이 포착해야 하는 실패입니다. |
| 시도당 타임아웃 제한 | 한 명의 느린 제공업체가 전체 백그라운드 작업을 중단시키지 않도록 최악의 경우의 벽시계 시간을 제한하십시오. |
| 단일 제공업체 내가 아닌 제공업체 간 페일오버 | 한 제공업체에서 429나 503이 발생하면 동일한 것을 재시도하는 대신 즉시 다른 제공업체로 라우팅해야 합니다. |
| 각 이벤트를 해결한 모델 기록 | 이것이 1계층 해결률을 측정하고 가격 및 신뢰성 변화에 따라 체인 순서를 재조정하는 방법입니다. |
| 원시 기록을 절대 삭제하지 않음 | 전체 체인 실패 시에도 원시 대화를 보관하십시오. 실패한 구조화된 요약은 복구 가능하지만 삭제된 기록은 복구할 수 없습니다. |
| 429/503 이외의 4xx 오류에 대한 알림 | 이는 보통 일시적인 제공업체 문제가 아니라 사용자의 스키마나 요청 버그를 나타내며, 영원히 조용히 재시도되어서는 안 됩니다. |
| 배포 전 제공업체별 SDK 오류 유형 확인 | 429, 5xx 및 타임아웃에 대한 예외 클래스는 제공업체 SDK마다 다르며 SDK 버전 간에도 변경됩니다. 가정하지 말고 현재 문서를 확인하십시오. |
개별 모델을 넘어선 제공업체 수준의 라우팅 결정에 대해서는 OpenRouter 비교 문서에서 다중 제공업체 라우팅이 속도 제한 및 페일오버 동작을 어떻게 변경하는지 다룹니다.
FAQ
AI 에이전트 메모리 통합이란 무엇인가?
원시 대화 기록을 장기 저장소에 기록되는 구조화되고 지속 가능한 메모리(사실, 선호도, 결정)로 변환하는 백그라운드 프로세스로, 일반적으로 세션 종료 시 강제 도구 호출이나 JSON 모드 완료를 통해 수행됩니다.
채팅을 차단하지 않고 비동기 백그라운드 메모리 통합을 구현하려면 어떻게 해야 하는가?
채팅 응답 경로와 분리하여 세션 종료 또는 유휴 타임아웃 시 백그라운드 작업자 작업으로 트리거하십시오. 작업자가 완료되면 메모리 저장소에 기록하며, 사용자의 다음 메시지는 이를 기다리지 않습니다. 이는 다중 모델 재시도 지연 시간을 허용 가능하게 만드는 요소이기도 합니다. 중요한 경로 밖에서 발생하기 때문입니다.
5-7개 모델 재시도 체인이 지연 시간이나 속도 제한 문제를 일으키지 않는가?
지연 시간 위험은 시도당 타임아웃으로 제한되며 통합을 비동기적으로 실행함으로써 흡수됩니다. 속도 제한 위험은 체인이 동일한 제공업체를 반복적으로 재시도하는 대신 서로 다른 제공업체 간에 페일오버하므로 완화됩니다. 따라서 한 모델의 429가 다른 제공업체의 할당량을 소모하거나 고갈시키지 않습니다. 이는 아키텍처적 완화 조치이며 측정된 지연 시간 수치가 아닙니다. 프로덕션 부하 상태에서 이 체인을 벤치마킹하지 않았습니다.
어떤 모델이 기본적으로 메모리 통합을 처리해야 하는가?
DeepSeek V4 Flash와 같이 볼륨에 적합한 가장 저렴하고 신뢰할 수 있는 모델로 시작하고, 그 뒤에 1계층으로 서로 다른 제공업체의 4~5개 모델을 체인으로 연결하십시오. Claude Sonnet 5와 Claude Opus 4.8은 2계층 에스컬레이션용으로만 예약하십시오. 순서를 확정하기 전에 TokenLab 모델 디렉토리에서 현재 가격을 확인하십시오.
폴백 체인의 모든 모델이 실패하면 어떻게 되는가?
원시 기록을 삭제하는 대신 통합되지 않은 상태로 보관하고, 담당자에게 알리고, 기록 자체(길이, 형식, 인코딩)가 모든 제공업체에서 실패를 유발하는지 확인하십시오. 7개의 독립적인 중단보다 공통 원인이 있을 가능성이 더 높기 때문입니다.
이것이 실제로 비용을 절감하는지 어떻게 알 수 있는가?
각 통합 이벤트를 해결하는 계층을 기록하고 위의 모델별 가격표를 사용하여 자체 데이터에서 혼합 비용을 계산하십시오. 빌려온 비율에 의존하지 마십시오. 해결률은 기록 길이, 스키마 엄격성 및 제공업체 신뢰성에 따라 달라집니다.
이 글에 작동하는 API 코드가 포함되지 않은 이유는 무엇인가?
이 증거 세트에는 체인에 포함된 7개 제공업체 모두에 대한 검증된 현재 엔드포인트, 인증 및 페이로드 세부 정보가 포함되어 있지 않으며, 그럴듯해 보이지만 검증되지 않은 요청 코드를 게시하는 것은 코드가 없는 것보다 더 나쁘기 때문입니다. 통합을 작성하기 전에 각 제공업체의 공식 API 참조에 대해 위의 검증 체크리스트를 사용하십시오.
시작하기
조용히 컨텍스트를 삭제할 여유가 없는 에이전트 메모리를 구축 중이라면, TokenLab을 시작하여 현재 가격을 비교하고 제공업체별 자격 증명 및 속도 제한을 관리하는 대신 단일 API 키를 통해 이 폴백 체인의 모델 전반에 걸쳐 통합 트래픽을 라우팅하십시오.
출처
2026-07-07 기준 가격
- fal PixVerse V6 model page2026-07-09 기준 확인
- fal FLUX.2 model page2026-07-09 기준 확인
- TokenLab model directory2026-07-07 기준 확인