ينهي المستخدم جلسة مدتها 30 دقيقة مع الوكيل الخاص بك. لقد شارك المتطلبات، وذكر التفضيلات، واتخذ القرارات. ثم يبدأ جلسة جديدة، ولا يتم نقل أي شيء من ذلك. ما تعطل عادةً ليس استنتاج الوكيل، بل توحيد ذاكرة وكيل الذكاء الاصطناعي (AI agent memory consolidation): وهي الخطوة الخلفية التي تحول النص الخام إلى ذاكرة منظمة طويلة المدى. تلك الخطوة عبارة عن استدعاء API واحد لنموذج واحد، واستدعاءات API الفردية تفشل. فحدود المعدل (Rate limits)، والمهلات (Timeouts)، ومخرجات الأدوات غير الصحيحة، كلها تنتج نفس العرض: فقدان صامت للذاكرة دون ظهور أي خطأ للمستخدم.
الإصلاح في هذه المقالة هو إصلاح معماري، وليس مجرد تحسين للمطالبة (Prompt): قم بتشغيل التوحيد من خلال سلسلة مرتبة من النماذج بدلاً من نموذج واحد، بحيث لا يؤدي الفشل لدى أي مزود إلى حذف المحادثة.
إذا كنت تبني واجهة المنتج المحيطة بدلاً من مجرد نظام الذاكرة الفرعي، فقم بإقران هذه الصفحة بـ دليل روبوت الدردشة بمفتاح واحد و دليل تحديد معدل API للذكاء الاصطناعي. إذا كنت تقارن بين المزودين بدلاً من النماذج الفردية، فاقرأ مقارنة OpenRouter بجانب هذه المقالة.
النقاط الرئيسية
- توحيد الذاكرة هو مهمة ضيقة ذات مخرجات منظمة (استدعاء أداة أو JSON إجباري)، وتتمتع استدعاءات المخرجات المنظمة بأنماط فشل أكثر من الدردشة الحرة: انتهاكات المخطط (schema)، والاقتطاع، وحدود المعدل، والمهلات.
- الاعتماد على نموذج واحد للتوحيد يمثل نقطة فشل واحدة. تعامل مع التوحيد كمشكلة موثوقية مع سلسلة احتياطية، وليس كمشكلة هندسة مطالبات.
- تعمل السلسلة المكونة من طبقتين بشكل جيد في الممارسة العملية: الطبقة الأولى هي سلسلة من النماذج منخفضة التكلفة (DeepSeek V4 Flash، GLM-5.2، Qwen3.7 Plus، Gemini 3.5 Flash، GPT-5.5) التي تفشل وتنتقل لبعضها البعض عند حدوث أي خطأ. الطبقة الثانية تصعد إلى Claude Sonnet 5، ثم Claude Opus 4.8، فقط عندما تفشل جميع نماذج الطبقة الأولى.
- لا تحتوي هذه المقالة على معدل فشل منشور وقابل للتكرار أو نسبة مئوية لخفض التكلفة لهذا وقت التشغيل (runtime) بالتحديد. حسابات التسعير أدناه توضيحية ومصنفة على هذا النحو. قم بقياس عبء العمل الخاص بك قبل الاستشهاد برقم.
- نظرًا لأن السلسلة تفشل وتنتقل عبر مزودين مستقلين بدلاً من إعادة محاولة مزود واحد بشكل متكرر، فإنها لا تركز الحمل على حد معدل واحد، ولأن التوحيد يعمل كوظيفة خلفية غير متزامنة (async)، فإن زمن انتقال إعادة المحاولة المضاف لا يعيق دورة الدردشة التي يراها المستخدم.
ما هو توحيد ذاكرة وكيل الذكاء الاصطناعي؟
توحيد الذاكرة هو عملية تحويل نص المحادثة الخام إلى حقائق منظمة ودائمة: تفضيلات المستخدم، والقرارات، وحالة المشروع، والكيانات المذكورة. وهي تختلف عن نافذة السياق النشطة للوكيل، التي تحمل رسائل الجلسة الحالية. يعمل التوحيد عادةً مرة واحدة لكل جلسة (عند الإغلاق، أو مهلة الخمول، أو نافذة متجددة) ويكتب مخرجاته في قاعدة بيانات، أو مخزن متجه (vector store)، أو خدمة ذاكرة بدلاً من إعادتها إلى الدردشة.
نظرًا لأن المخرجات يجب أن تتطابق مع مخطط (حتى تتمكن كود الاسترجاع اللاحق من استخدامه)، يتم تنفيذ التوحيد دائمًا تقريبًا كاستدعاء أداة إجباري أو إكمال في وضع JSON، وليس كإجابة دردشة عادية. هذه هي التفاصيل التي تجعلها هشة: يمكن للنموذج إجراء محادثة جيدة تمامًا ومع ذلك يفشل في خطوة التوحيد عن طريق إرجاع نص بدلاً من استدعاء الأداة، أو اقتطاع JSON في نص طويل، أو اختراع حقل لا يتضمنه مخططك.
لماذا يفشل التوحيد بنموذج واحد
تحتوي استدعاءات المخرجات المنظمة على أنماط فشل أكثر من إكمال الدردشة العادي:
- يتجاهل النموذج مخطط الأداة ويعيد نصًا بدلاً من استدعاء الأداة.
- يعيد المزود حد معدل (429) أو خطأ خادم (500/502/503) أثناء ذروة حركة المرور.
- تنتهي مهلة الطلب، غالبًا في النصوص الطويلة التي تتطلب رموزًا (tokens) أكثر للتلخيص.
- يعيد النموذج JSON صالحًا مع اسم حقل أو نوع لا يتطابق مع مخططك.
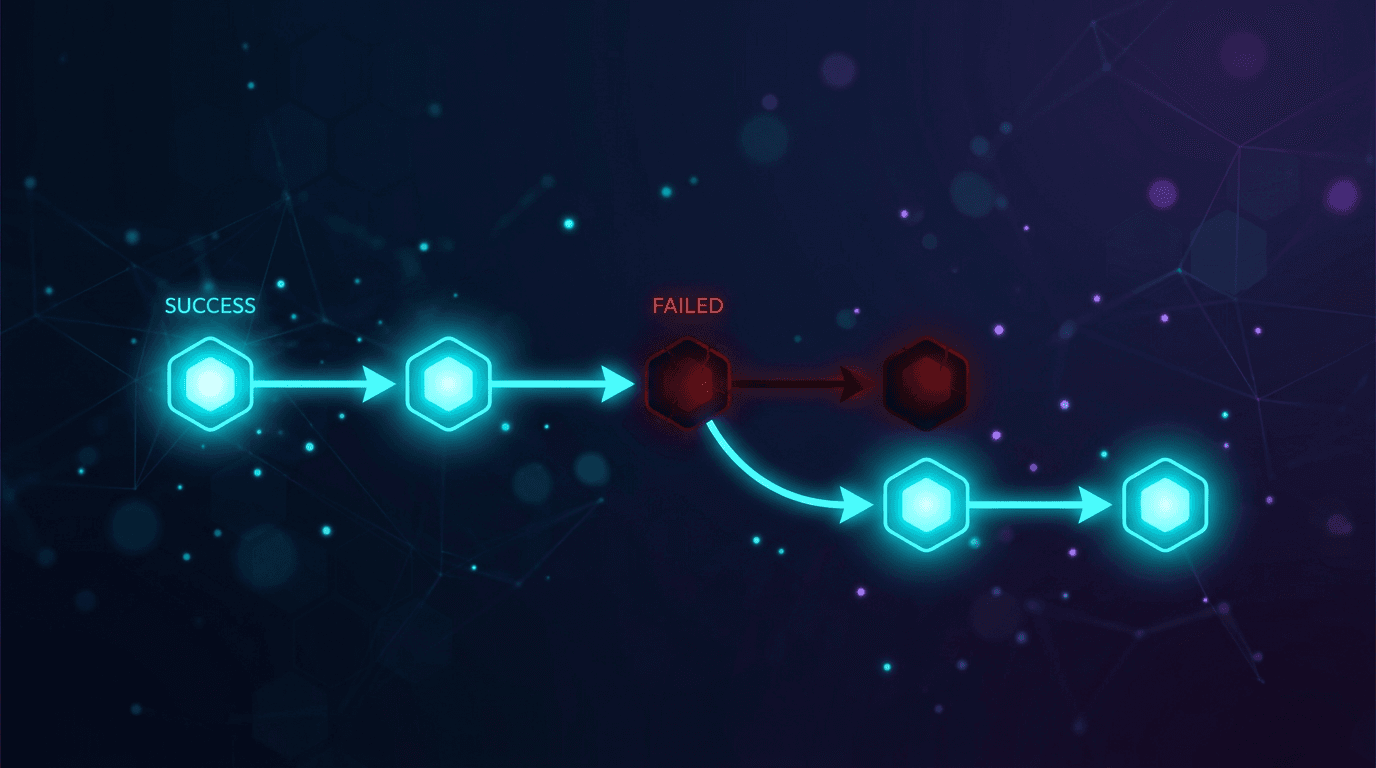
أي من هذه الأمور يحول المحادثة المكتملة إلى فجوة ذاكرة صامتة. لا يظهر أي خطأ للمستخدم. يلاحظون ذلك لاحقًا، عندما "ينسى" الوكيل شيئًا ما، وبحلول ذلك الوقت قد يكون النص الخام قد اختفى بالفعل إذا لم تقم بحفظه بشكل منفصل.
لم ننشر معيارًا لمعدل الفشل الخاضع للرقابة لوقت التشغيل أو عبء العمل أو التاريخ هذا بالتحديد، لذا لن نعيد ذكر نسبة مئوية محددة هنا. ما يمكن التحقق منه هو الآلية: أنماط الفشل الأربعة المحددة أعلاه، والتي يتم القضاء عليها جميعًا كنقاط فشل واحدة بمجرد ربط النماذج بدلاً من استدعاء نموذج واحد.
تسعير النماذج للسلسلة الاحتياطية
يسرد الجدول أدناه أسعار TokenLab الحالية للنماذج المستخدمة في السلسلة الاحتياطية الموضحة في هذه المقالة. هذه لقطة حية لأسعار TokenLab، تختلف عن أي وثائق منشورة من قبل المزود. تحقق من هذه الأسعار قبل تأكيد الطلب، حيث يتغير تسعير الرمز المميز بمرور الوقت.
| النموذج | نافذة السياق | الإدخال $/MTok | الإخراج $/MTok | المصدر | تم الرصد |
|---|---|---|---|---|---|
| DeepSeek V4 Flash | 1,048,576 | $0.09 | $0.18 | لقطة حية لنموذج/أسعار TokenLab | 2026-07-09 |
| GLM-5.2 | 1,048,576 | $0.93 | $3.00 | لقطة حية لنموذج/أسعار TokenLab | 2026-07-09 |
| Qwen3.7 Plus | 1,000,000 | $0.32 | $1.28 | لقطة حية لنموذج/أسعار TokenLab | 2026-07-09 |
| Gemini 3.5 Flash | 1,048,576 | $1.50 | $9.00 | لقطة حية لنموذج/أسعار TokenLab | 2026-07-09 |
| GPT-5.5 | 1,050,000 | $5.00 | $30.00 | لقطة حية لنموذج/أسعار TokenLab | 2026-07-09 |
| Claude Sonnet 5 | 1,000,000 | $2.00 | $10.00 | لقطة حية لنموذج/أسعار TokenLab | 2026-07-09 |
| Claude Opus 4.8 | 1,000,000 | $5.00 | $25.00 | لقطة حية لنموذج/أسعار TokenLab | 2026-07-09 |
للحصول على حدود المعدل الحية، وأحدث الأسعار، وتصنيفات الموثوقية، تحقق من دليل نماذج TokenLab و لوحة صدارة النماذج قبل إنهاء ترتيب السلسلة الخاصة بك.
إذا كنت توجه حركة مرور توحيد الذاكرة في الإنتاج، ابدأ مع TokenLab للوصول إلى جميع هذه النماذج السبعة من خلال مفتاح API واحد بدلاً من إدارة بيانات اعتماد منفصلة، وحدود معدل، وتنسيقات خطأ لكل مزود.
بنية الاحتياطي ثنائية الطبقات
الطبقة الأولى: رخيصة، عالية الحجم، متنوعة المزودين
تعمل هذه الطبقة في كل حدث توحيد. اربط النماذج عبر ثلاثة مزودين مختلفين على الأقل، بهذا الترتيب:
- DeepSeek V4 Flash
- GLM-5.2
- Qwen3.7 Plus
- Gemini 3.5 Flash
- GPT-5.5
عند حدوث أي فشل في استدعاء الأداة، أو انتهاك للمخطط، أو مهلة، أو استجابة 4xx/5xx، انتقل فورًا إلى النموذج التالي في القائمة. لا تعد محاولة نفس النموذج في الطبقة الأولى؛ فحد المعدل أو الاستجابة غير الصحيحة من المرجح أن تتكرر بدلاً من أن تُحل عند إعادة محاولة فورية.
الطبقة الثانية: التصعيد لحالات الحافة الحقيقية
إذا فشل كل نموذج في الطبقة الأولى، صعد إلى نموذج أقوى بدلاً من العودة عبر الطبقة الأولى:
- Claude Sonnet 5
- Claude Opus 4.8 (الاحتياطي النهائي)
يجب أن تكون الطبقة الثانية نادرة. إذا رأيت تصعيدات متكررة للطبقة الثانية في سجلاتك، فهذه إشارة للتحقق من ترتيب الطبقة الأولى، أو صرامة المخطط الخاص بك، أو طول النص، وليس سببًا لجعل الطبقة الثانية مسارك الافتراضي.
كيفية تنفيذ توحيد الذاكرة الخلفي غير المتزامن
لا ينبغي للتوحيد أبدًا أن يعيق الرسالة التالية للمستخدم. قم بتشغيله كوظيفة خلفية يتم تشغيلها عند إغلاق الجلسة أو مهلة الخمول، والكتابة في مخزن الذاكرة الخاص بك عند اكتمالها، وليس بشكل مضمن في مسار استجابة الدردشة. هذا الفصل هو أيضًا ما يجعل زمن الانتقال في أسوأ الحالات لسلسلة متعددة النماذج مقبولًا: بضع ثوانٍ إضافية من إعادة المحاولة في عامل خلفي ليس لها أي تأثير على دورة المستخدم.
تدفق التحكم، الموصوف بدون كود، هو:
- عند إغلاق الجلسة أو مهلة الخمول، قم بوضع وظيفة خلفية في قائمة الانتظار مع النص الكامل.
- يحاول العامل إجراء التوحيد مقابل النموذج الأول في قائمة الطبقة الأولى، مع مهلة محدودة لكل محاولة.
- عند حدوث مهلة، أو 429، أو 5xx، ينتقل العامل إلى النموذج التالي في القائمة فورًا، دون إعادة محاولة في نفس المكان مقابل نفس النموذج.
- عند استجابة 200، يتحقق العامل من الحمولة مقابل مخطط JSON الخاص بك قبل قبولها. يتم التعامل مع الاستجابة التي تجتاز فحص حالة HTTP ولكنها تفشل في التحقق من المخطط بنفس طريقة فشل الشبكة: قم بتسجيلها وانتقل إلى النموذج التالي.
- إذا فشل كل نموذج في الطبقة الأولى، يصعد العامل إلى الطبقة الثانية (Claude Sonnet 5، ثم Claude Opus 4.8) باستخدام نفس منطق المهلة والتحقق.
- إذا فشل كل نموذج في كلتا الطبقتين، يقوم العامل بحفظ النص الخام غير الموحد في التخزين وتنبيه مهندس المناوبة. لا يتم التخلص من النص الخام أبدًا، بغض النظر عن كيفية حل التوحيد.
- سجل النموذج الذي حل كل حدث (أو أن السلسلة الكاملة فشلت) حتى تتمكن من قياس معدل حل الطبقة الأولى الخاص بك وإعادة ترتيب السلسلة لاحقًا.
نحن لا ننشر نموذج كود قابل للنسخ واللصق مع أسماء طرق SDK محددة، أو حمولات طلب، أو أشكال استجابة لهؤلاء المزودين السبعة، لأن مجموعة الأدلة هذه لا تحتوي على تفاصيل نقطة النهاية، والمصادقة، والحمولة التي تم التحقق منها لكل واحد، واختراعها سينتج كود تكامل يبدو صحيحًا ولكنه يفشل بصمت في الإنتاج. قبل تنفيذ هذا التدفق، اعمل من خلال قائمة التحقق من التحقق أدناه مقابل وثائق كل مزود.
قائمة التحقق من التحقق قبل التنفيذ
- تأكد من نقطة النهاية الحالية، وتنسيق رأس المصادقة، وشكل جسم الطلب لوضع المخرجات المنظمة أو استدعاء الأداة لكل مزود مباشرة من مرجع API الرسمي الخاص بهم، وليس من ملخص طرف ثالث.
- تأكد من الاستثناء أو كائن الخطأ الذي يرفعه SDK الخاص بكل مزود لـ 429، و500/502/503، ومهلات جانب العميل، حيث تختلف هذه حسب SDK وتتغير عبر إصدارات SDK.
- تأكد مما إذا كانت مكتبة عميل كل مزود تحتوي على آلية إعادة محاولة مدمجة تحتاج إلى تعطيلها، حيث تريد تجاوز الفشل عبر المزودين في هذه السلسلة، وليس إعادة محاولة داخل المكتبة مقابل نفس النموذج.
- تأكد من أن مدقق مخطط JSON الخاص بك يعمل على كل استجابة قبل وصولها إلى
persist_memory، بما في ذلك الاستجابات التي تعيد HTTP 200. - إذا كنت توجه عبر بوابة متعددة المزودين مثل TokenLab بدلاً من الاتصال بكل مزود مباشرة، فتأكد من تنسيق تمرير الخطأ الخاص بالبوابة في وثائقها على tokenlab.sh/en/models قبل افتراض أن رموز الخطأ الخاصة بالمزود تنتشر دون تغيير.
ملاحظات معالجة الأخطاء، مرتبطة بفئات الفشل الحقيقية
| فئة الخطأ | المعالجة |
|---|---|
| 429 حد المعدل | انتقل إلى النموذج التالي فورًا. لا تعد محاولة نفس النموذج في الحلقة. إذا قام نموذج واحد بتحديد المعدل بشكل متكرر، أضف فترة تهدئة قصيرة قبل تجربته مرة أخرى في الاستدعاءات المستقبلية. |
| 500/502/503 خطأ خادم | تعامل معه كخطأ عابر. انتقل إلى النموذج التالي. لا تضف تراجعًا أسيًا (exponential backoff) داخل هذه السلسلة؛ فالفشل في الانتقال إلى مزود مختلف أسرع من انتظار انقطاع مزود واحد. |
| مهلة | حدد مهلة لكل محاولة (حد توضيحي من 5-10 ثوانٍ لكل استدعاء؛ اضبطه حسب طول النص الخاص بك). عند حدوث مهلة، انتقل إلى النموذج التالي بدلاً من تمديد الانتظار. |
| 4xx بخلاف 429 | عادةً ما يكون خطأ في تنسيق الطلب من جانبك. سجل بصوت عالٍ ونبه إنسانًا؛ لا تدعه يفشل بصمت إلى الأبد دون رؤية. |
| 200 OK مع جسم غير صحيح | تحقق مقابل مخطط JSON الخاص بك قبل القبول. الاستجابة الصالحة نحويًا ذات الشكل الخاطئ لا تزال فشلًا ويجب اكتشافها بواسطة التحقق، وليس فقط بواسطة حالة HTTP. |
حول اعتراض "هل يسبب هذا استنفاد حد المعدل": يجلس كل نموذج من الطبقة الأولى خلف مزود مختلف، لذا فإن 429 على أحدهم لا تستهلك حصة مزود آخر. السلسلة تنشر الحمل بدلاً من تركيزه. في أسوأ الحالات، خمس محاولات للطبقة الأولى بالإضافة إلى محاولتين للطبقة الثانية هي سبعة استدعاءات؛ بحد أقصى للمهلة 8 ثوانٍ لكل محاولة، يحد ذلك من أسوأ الحالات بحوالي دقيقة، ويتطلب هذا السيناريو فشل كل مزود في وقت واحد، وهي حالة الحافة النادرة التي صُممت هذه البنية للنجاة منها، وليس المسار الشائع. هذا حد يعتمد على المهلات التي تقوم بتكوينها، وليس معيار زمن انتقال إنتاج مقاس؛ لم نقم بتشغيل هذه السلسلة تحت الحمل ولا نبلغ عن p50/p99 مقاس.
مقارنة تكلفة توضيحية عبر السلسلة الاحتياطية
لإظهار سبب أهمية توجيه معظم الحجم عبر نماذج رخيصة، إليك مثال عملي باستخدام جدول الأسعار أعلاه. الافتراض: استدعاء توحيد متوسط يرسل نصًا من 3000 رمز كإدخال وينتج 400 رمز من المخرجات المنظمة. هذا افتراض توضيحي، وليس متوسطًا مقاسًا من أي عبء عمل عميل محدد؛ استبدل بأعداد الرموز الخاصة بك.
| النموذج | التكلفة لكل استدعاء (الافتراض أعلاه) |
|---|---|
| DeepSeek V4 Flash | $0.00034 |
| Qwen3.7 Plus | $0.00147 |
| GLM-5.2 | $0.00399 |
| Gemini 3.5 Flash | $0.00810 |
| Claude Sonnet 5 | $0.01000 |
| Claude Opus 4.8 | $0.02500 |
| GPT-5.5 | $0.02700 |
الفارق حقيقي: توجيه 100% من الاستدعاءات عبر GPT-5.5 يكلف حوالي 80 ضعفًا لكل استدعاء أكثر من التوجيه عبر DeepSeek V4 Flash، بموجب هذا الافتراض. ما لا يمكننا ذكره بدون بياناتك الخاصة هو جزء حركة المرور الخاص بك الذي يتم حله فعليًا في الطبقة الأولى مقابل التصعيد إلى الطبقة الثانية، لأن ذلك يعتمد على طول النص الخاص بك، وتعقيد المخطط، وموثوقية المزود في اليوم الذي تقوم فيه بتشغيله. سجل النموذج الذي يحل كل حدث (الخطوة 7 في تدفق التنفيذ أعلاه) واحسب تكلفتك الممزوجة بعد بضعة آلاف من الأحداث بدلاً من الاعتماد على نسبة مئوية مستعارة.
القيود
- لا يوجد معيار عام وقابل للتكرار لمعدل الفشل لهذه السلسلة أو عبء العمل أو التاريخ في مجموعة الأدلة هذه. قم بتجهيز السجلات في وقت التشغيل الخاص بك قبل الاستشهاد برقم محدد.
- يستخدم جدول التكلفة أعلاه عدد رموز مفترض، وليس متوسط طول نص مقاس. أعد الحساب بأرقامك الخاصة باستخدام مصدر جدول الأسعار وتاريخ الرصد.
- تتغير أسعار النماذج ونوافذ السياق. تأكد من القيم الحالية على دليل نماذج TokenLab قبل إنهاء ترتيب السلسلة للإنتاج.
- تقلل السلسلة الاحتياطية من مخاطر نقطة الفشل الواحدة؛ لكنها لا تضمن فقدان بيانات صفري. احفظ دائمًا النص الخام بشكل منفصل عن مخرجات التوحيد المنظمة.
- أرقام زمن الانتقال واستنفاد حد المعدل في هذه المقالة هي تقديرات تعتمد على مهلات قابلة للتكوين، وليس معايير إنتاج مقاسة. لم نقم بتشغيل هذه السلسلة تحت الحمل في مجموعة الأدلة هذه.
- هذه المقالة لا تتضمن عمدًا كود طلب قابل للنسخ واللصق، لأن تفاصيل نقطة النهاية الدقيقة، ورأس المصادقة، والحمولة لهؤلاء المزودين السبعة لم تكن متاحة للتحقق في وقت الكتابة. استخدم قائمة التحقق من التحقق ووثائق كل مزود الرسمية قبل التنفيذ.
قائمة التحقق من التنفيذ
| الممارسة | لماذا تهم |
|---|---|
| التحقق من المخطط، وليس فقط حالة HTTP | استجابة 200 مع JSON غير صحيح أو استدعاء أداة مفقود لا تزال فشلًا يجب أن تلتقطه منطق إعادة المحاولة الخاص بك. |
| تحديد مهلة لكل محاولة | حدد وقت الساعة الحائطية لأسوأ الحالات حتى لا يعيق مزود بطيء وظيفة الخلفية بأكملها. |
| الفشل عبر المزودين، وليس داخل واحد | يجب أن يوجه 429 أو 503 على مزود واحد إلى مزود مختلف فورًا بدلاً من إعادة محاولة نفس المزود. |
| سجل النموذج الذي حل كل حدث | هذه هي الطريقة التي تقيس بها معدل حل الطبقة الأولى الخاص بك وتعيد ترتيب السلسلة مع تغير الأسعار والموثوقية. |
| لا تسقط النص الخام أبدًا | حتى عند فشل السلسلة الكاملة، احفظ المحادثة الخام. الملخص المنظم الفاشل قابل للاسترداد؛ أما النص المحذوف فلا. |
| تنبيه بشأن أخطاء 4xx بخلاف 429/503 | تشير هذه عادةً إلى خطأ في المخطط أو الطلب من جانبك، وليس مشكلة مزود عابرة، ولا ينبغي إعادة محاولتها بصمت إلى الأبد. |
| تحقق من أنواع خطأ SDK لكل مزود قبل النشر | تختلف فئات الاستثناء لـ 429، و5xx، والمهلات عبر SDKs المزود وتتغير بين إصدارات SDK؛ تحقق من الوثائق الحالية بدلاً من الافتراض. |
بالنسبة لقرارات التوجيه على مستوى المزود خارج النماذج الفردية، تغطي مقارنة OpenRouter كيفية تغيير التوجيه متعدد المزودين لسلوك حد المعدل وتجاوز الفشل.
الأسئلة الشائعة
ما هو توحيد ذاكرة وكيل الذكاء الاصطناعي؟
العملية الخلفية التي تحول نص المحادثة الخام إلى ذاكرة منظمة ودائمة (حقائق، تفضيلات، قرارات) مكتوبة في تخزين طويل المدى، عادةً عبر استدعاء أداة إجباري أو إكمال في وضع JSON في نهاية الجلسة.
كيف أنفذ توحيد الذاكرة الخلفي غير المتزامن دون إعاقة الدردشة؟
قم بتشغيله عند إغلاق الجلسة أو مهلة الخمول كوظيفة عامل خلفي، منفصلة عن مسار استجابة الدردشة. يكتب العامل في مخزن الذاكرة الخاص بك عند انتهائه؛ ولا تنتظر الرسالة التالية للمستخدم. هذا هو أيضًا ما يجعل زمن انتقال إعادة المحاولة متعدد النماذج مقبولًا، لأنه يحدث خارج المسار الحرج.
هل ستتسبب سلسلة إعادة المحاولة المكونة من 5-7 نماذج في مشاكل زمن انتقال أو حد معدل؟
يتم تحديد مخاطر زمن الانتقال من خلال مهلة كل محاولة ويتم استيعابها عن طريق تشغيل التوحيد بشكل غير متزامن. يتم تخفيف مخاطر حد المعدل لأن السلسلة تفشل عبر مزودين مختلفين بدلاً من إعادة محاولة مزود واحد بشكل متكرر، لذا فإن 429 على نموذج واحد لا تضغط أو تستنفد حصة مزود آخر. هذه تخفيفات معمارية، وليست أرقام زمن انتقال مقاسة؛ لم نقم بقياس هذه السلسلة تحت حمل الإنتاج.
أي نموذج يجب أن يتعامل مع توحيد الذاكرة افتراضيًا؟
ابدأ بالنموذج الموثوق الأرخص لحجمك، مثل DeepSeek V4 Flash، واربط أربعة أو خمسة نماذج عبر مزودين مختلفين خلفه كطبقة أولى. احتفظ بـ Claude Sonnet 5 و Claude Opus 4.8 كتصعيد للطبقة الثانية فقط. تحقق من الأسعار الحالية على دليل نماذج TokenLab قبل إنهاء الترتيب.
ماذا يحدث إذا فشل كل نموذج في السلسلة الاحتياطية؟
احفظ النص الخام غير الموحد بدلاً من التخلص منه، ونبه إنسانًا، وتحقق مما إذا كان النص نفسه (الطول، التنسيق، الترميز) هو الذي يسبب الفشل عبر كل مزود، لأن السبب المشترك أكثر احتمالًا من سبعة انقطاعات مستقلة.
كيف أعرف ما إذا كان هذا يقلل تكلفتي فعليًا؟
سجل الطبقة التي تحل كل حدث توحيد واحسب التكلفة الممزوجة من بياناتك الخاصة باستخدام جدول التسعير لكل نموذج أعلاه. لا تعتمد على نسبة مئوية مستعارة؛ يعتمد معدل الحل الخاص بك على طول النص الخاص بك، وصرامة المخطط، وموثوقية المزود.
لماذا لا تتضمن هذه المقالة كود API يعمل؟
لأن مجموعة الأدلة هذه لا تحتوي على تفاصيل نقطة النهاية، والمصادقة، والحمولة الحالية التي تم التحقق منها لجميع المزودين السبعة في السلسلة، ونشر كود طلب يبدو معقولًا ولكنه غير محقق سيكون أسوأ من عدم وجود كود على الإطلاق. استخدم قائمة التحقق من التحقق أعلاه مقابل مرجع API الرسمي لكل مزود قبل كتابة التكامل الخاص بك.
ابدأ
إذا كنت تبني ذاكرة وكيل لا يمكنها تحمل فقدان السياق بصمت، ابدأ مع TokenLab لمقارنة الأسعار الحالية وتوجيه حركة مرور التوحيد عبر النماذج في هذه السلسلة الاحتياطية من خلال مفتاح API واحد، بدلاً من إدارة بيانات اعتماد منفصلة وحدود معدل لكل مزود.
المصادر
تم رصد السعر في 2026-07-07
- fal PixVerse V6 model pageتمت المراجعة في 2026-07-09
- fal FLUX.2 model pageتمت المراجعة في 2026-07-09
- TokenLab model directoryتمت المراجعة في 2026-07-07