Seorang pengguna menyelesaikan sesi 30 menit dengan agen Anda. Mereka telah membagikan kebutuhan, menyatakan preferensi, dan membuat keputusan. Kemudian mereka memulai sesi baru, dan tidak ada satu pun informasi yang terbawa. Hal yang biasanya rusak bukanlah penalaran agen tersebut, melainkan konsolidasi memori agen AI: langkah latar belakang yang mengubah transkrip mentah menjadi memori jangka panjang yang terstruktur. Langkah tersebut adalah satu panggilan API ke satu model, dan panggilan API tunggal bisa gagal. Limit rate, timeout, dan output tool yang tidak sesuai, semuanya menghasilkan gejala yang sama: kehilangan memori secara diam-diam tanpa ada kesalahan yang ditampilkan kepada pengguna.
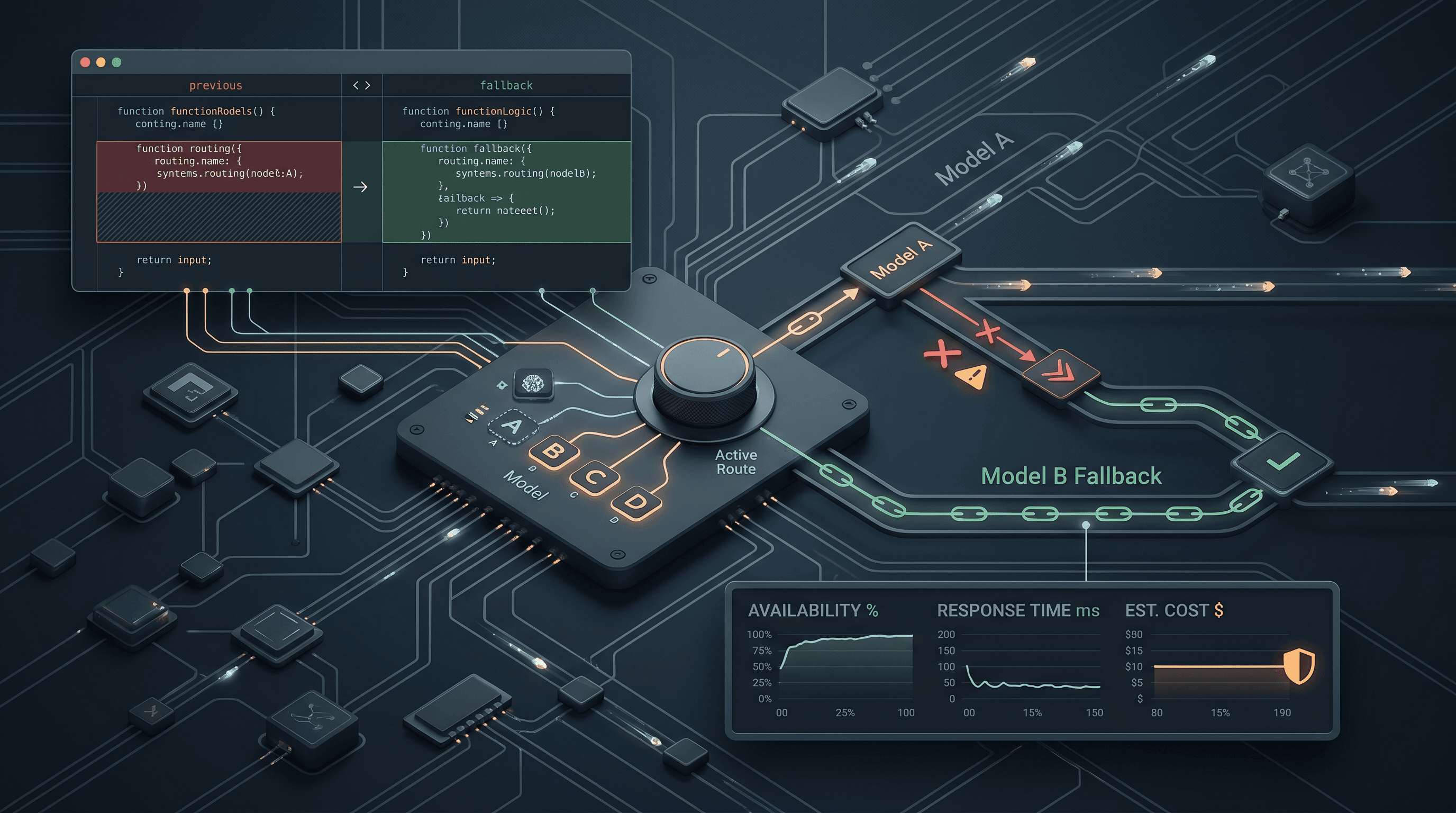
Perbaikan dalam artikel ini bersifat arsitektural, bukan sekadar prompt yang lebih baik: jalankan konsolidasi melalui rantai model yang terurut alih-alih satu model, sehingga kegagalan pada penyedia mana pun tidak akan menghapus percakapan tersebut.
Jika Anda membangun permukaan produk di sekitarnya alih-alih hanya subsistem memori, pasangkan halaman ini dengan panduan chatbot satu kunci dan panduan limit rate API AI. Jika Anda membandingkan penyedia alih-alih model individu, baca perbandingan OpenRouter bersama dengan artikel ini.
Poin-Poin Penting
- Konsolidasi memori adalah tugas output terstruktur yang sempit (pemanggilan tool atau JSON paksa), dan panggilan output terstruktur memiliki lebih banyak mode kegagalan daripada chat bebas: pelanggaran skema, pemotongan (truncation), limit rate, dan timeout.
- Satu model yang menangani konsolidasi adalah titik kegagalan tunggal (single point of failure). Perlakukan konsolidasi sebagai masalah keandalan dengan rantai fallback, bukan masalah rekayasa prompt.
- Rantai dua lapis bekerja dengan baik dalam praktiknya: Lapis 1 adalah urutan model berbiaya rendah (DeepSeek V4 Flash, GLM-5.2, Qwen3.7 Plus, Gemini 3.5 Flash, GPT-5.5) yang melakukan failover satu sama lain jika terjadi kesalahan. Lapis 2 meningkat ke Claude Sonnet 5, lalu Claude Opus 4.8, hanya jika setiap model Lapis 1 gagal.
- Artikel ini tidak memiliki tingkat kegagalan atau persentase pengurangan biaya yang dipublikasikan dan dapat direproduksi untuk runtime yang tepat ini. Perhitungan harga di bawah ini bersifat ilustratif dan diberi label demikian. Ukur beban kerja Anda sendiri sebelum mengutip angka.
- Karena rantai melakukan failover di seluruh penyedia independen alih-alih mencoba ulang satu penyedia berulang kali, hal ini tidak memusatkan beban pada satu limit rate, dan karena konsolidasi berjalan sebagai pekerjaan latar belakang asinkron, latensi percobaan ulang tambahan tidak akan memblokir giliran chat yang dihadapi pengguna.
Apa itu konsolidasi memori agen AI?
Konsolidasi memori adalah proses mengubah transkrip percakapan mentah menjadi fakta yang terstruktur dan tahan lama: preferensi pengguna, keputusan, status proyek, dan entitas yang disebutkan. Ini berbeda dari jendela konteks aktif agen, yang menampung pesan sesi saat ini. Konsolidasi biasanya berjalan sekali per sesi (saat ditutup, saat timeout idle, atau pada jendela bergulir) dan menulis outputnya ke database, penyimpanan vektor, atau layanan memori alih-alih kembali ke chat.
Karena output harus sesuai dengan skema (sehingga kode pengambilan data hilir dapat menggunakannya), konsolidasi hampir selalu diimplementasikan sebagai pemanggilan tool paksa atau penyelesaian mode JSON, bukan balasan chat biasa. Itulah detail yang membuatnya rapuh: model dapat melakukan percakapan dengan sangat baik namun tetap gagal pada langkah konsolidasi dengan mengembalikan prosa alih-alih pemanggilan tool, memotong JSON pada transkrip yang panjang, atau menciptakan bidang yang tidak dimiliki skema Anda.
Mengapa konsolidasi model tunggal gagal
Panggilan output terstruktur memiliki lebih banyak mode kegagalan daripada penyelesaian chat normal:
- Model mengabaikan skema tool dan mengembalikan prosa alih-alih pemanggilan tool.
- Penyedia mengembalikan limit rate (429) atau kesalahan server (500/502/503) selama lonjakan lalu lintas.
- Permintaan mengalami timeout, sering kali pada transkrip yang lebih panjang yang membutuhkan lebih banyak token untuk diringkas.
- Model mengembalikan JSON yang valid dengan nama bidang atau tipe yang tidak sesuai dengan skema Anda.
Salah satu dari hal ini mengubah percakapan yang selesai menjadi celah memori yang diam. Tidak ada kesalahan yang ditampilkan kepada pengguna. Mereka baru menyadarinya nanti, ketika agen "lupa" sesuatu, dan pada saat itu transkrip mentah mungkin sudah hilang jika Anda tidak menyimpannya secara terpisah.
Kami belum memublikasikan tolok ukur tingkat kegagalan terkontrol untuk runtime, beban kerja, atau tanggal yang tepat ini, jadi kami tidak akan menyatakan persentase spesifik di sini. Yang dapat diverifikasi adalah mekanismenya: empat mode kegagalan konkret yang disebutkan di atas, yang semuanya dihilangkan sebagai titik kegagalan tunggal setelah Anda merantai model alih-alih memanggil satu model saja.
Harga model untuk rantai fallback
Tabel di bawah mencantumkan harga TokenLab saat ini untuk model yang digunakan dalam rantai fallback yang dijelaskan dalam artikel ini. Ini adalah cuplikan harga langsung TokenLab, berbeda dari dokumentasi yang dipublikasikan penyedia mana pun. Verifikasi harga ini sebelum mengunci pesanan, karena harga per token berubah seiring waktu.
| Model | Jendela konteks | Input $/MTok | Output $/MTok | Sumber | Diamati |
|---|---|---|---|---|---|
| DeepSeek V4 Flash | 1.048.576 | $0,09 | $0,18 | Cuplikan harga/model langsung TokenLab | 09-07-2026 |
| GLM-5.2 | 1.048.576 | $0,93 | $3,00 | Cuplikan harga/model langsung TokenLab | 09-07-2026 |
| Qwen3.7 Plus | 1.000.000 | $0,32 | $1,28 | Cuplikan harga/model langsung TokenLab | 09-07-2026 |
| Gemini 3.5 Flash | 1.048.576 | $1,50 | $9,00 | Cuplikan harga/model langsung TokenLab | 09-07-2026 |
| GPT-5.5 | 1.050.000 | $5,00 | $30,00 | Cuplikan harga/model langsung TokenLab | 09-07-2026 |
| Claude Sonnet 5 | 1.000.000 | $2,00 | $10,00 | Cuplikan harga/model langsung TokenLab | 09-07-2026 |
| Claude Opus 4.8 | 1.000.000 | $5,00 | $25,00 | Cuplikan harga/model langsung TokenLab | 09-07-2026 |
Untuk limit rate langsung, harga terbaru, dan peringkat keandalan, periksa direktori model TokenLab dan papan peringkat model sebelum menyelesaikan urutan rantai Anda.
Jika Anda merutekan lalu lintas konsolidasi memori dalam produksi, mulailah dengan TokenLab untuk menjangkau ketujuh model ini melalui satu kunci API alih-alih mengelola kredensial, limit rate, dan format kesalahan yang terpisah per penyedia.
Arsitektur fallback dua lapis
Lapis 1: murah, volume tinggi, beragam penyedia
Lapis ini berjalan pada setiap peristiwa konsolidasi. Rantai model di setidaknya tiga penyedia berbeda, dalam urutan ini:
- DeepSeek V4 Flash
- GLM-5.2
- Qwen3.7 Plus
- Gemini 3.5 Flash
- GPT-5.5
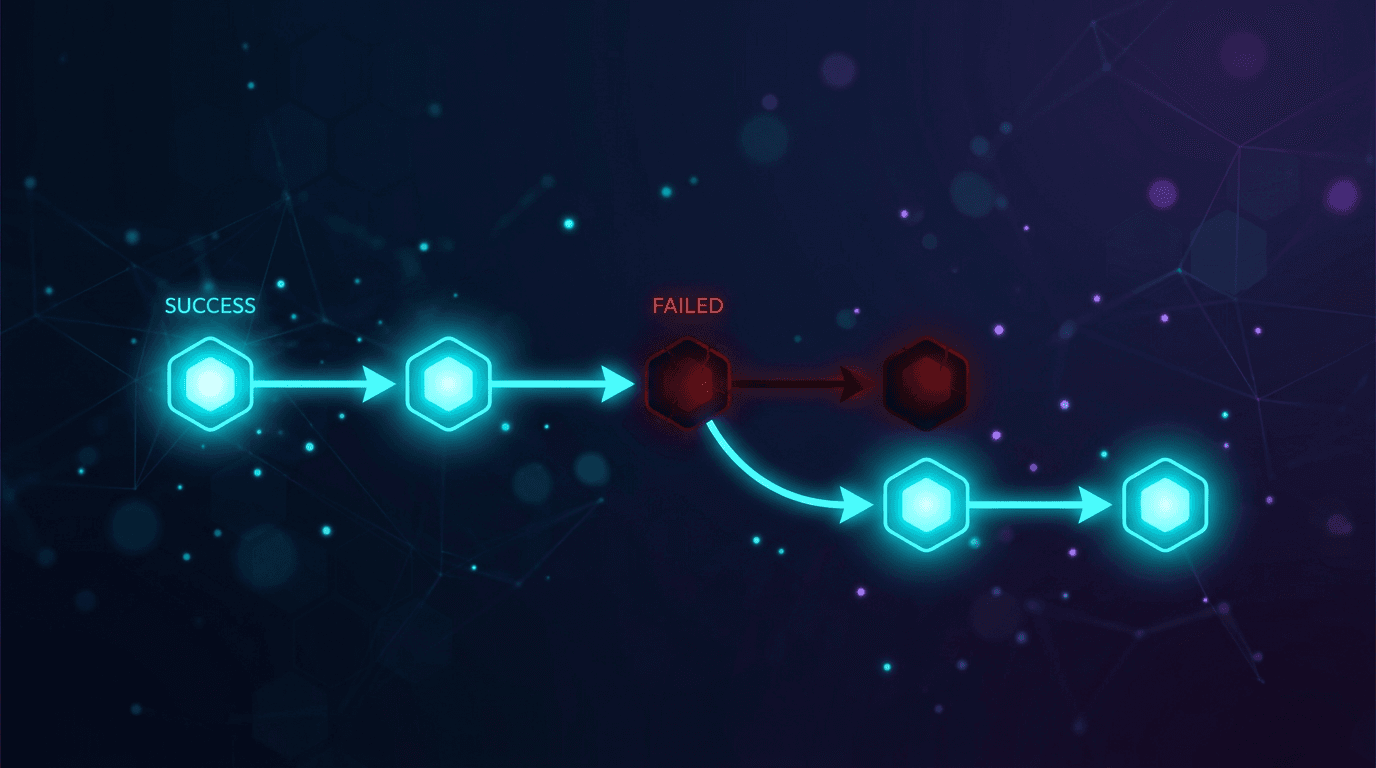
Jika terjadi kegagalan pemanggilan tool, pelanggaran skema, timeout, atau respons 4xx/5xx, segera pindah ke model berikutnya dalam daftar. Jangan mencoba ulang model yang sama di Lapis 1; limit rate atau respons yang cacat lebih mungkin terulang daripada teratasi pada percobaan ulang instan.
Lapis 2: eskalasi untuk kasus tepi yang nyata
Jika setiap model Lapis 1 gagal, tingkatkan ke model yang lebih kuat alih-alih kembali melalui Lapis 1:
- Claude Sonnet 5
- Claude Opus 4.8 (fallback terakhir)
Lapis 2 seharusnya jarang terjadi. Jika Anda sering melihat eskalasi Lapis 2 di log Anda, itu adalah sinyal untuk memeriksa urutan Lapis 1, keketatan skema, atau panjang transkrip Anda, bukan alasan untuk menjadikan Lapis 2 sebagai jalur default Anda.
Cara mengimplementasikan konsolidasi memori latar belakang asinkron
Konsolidasi tidak boleh memblokir pesan pengguna berikutnya. Jalankan sebagai pekerjaan latar belakang yang dipicu saat sesi ditutup atau timeout idle, menulis ke penyimpanan memori Anda saat selesai, bukan secara inline di jalur respons chat. Pemisahan ini juga yang membuat latensi kasus terburuk dari rantai multi-model dapat diterima: beberapa detik tambahan percobaan ulang di pekerja latar belakang tidak berpengaruh pada giliran yang dihadapi pengguna.
Alur kontrolnya, yang dijelaskan tanpa kode, adalah:
- Saat sesi ditutup atau timeout idle, masukkan pekerjaan latar belakang dengan transkrip lengkap.
- Pekerja mencoba konsolidasi terhadap model pertama dalam daftar Lapis 1, dengan timeout per percobaan yang dibatasi.
- Saat timeout, 429, atau 5xx, pekerja segera pindah ke model berikutnya dalam daftar, tanpa percobaan ulang di tempat terhadap model yang sama.
- Saat respons 200, pekerja memvalidasi payload terhadap skema JSON Anda sebelum menerimanya. Respons yang lolos pemeriksaan status HTTP tetapi gagal validasi skema diperlakukan sama dengan kegagalan jaringan: catat dan pindah ke model berikutnya.
- Jika setiap model Lapis 1 gagal, pekerja meningkat ke Lapis 2 (Claude Sonnet 5, lalu Claude Opus 4.8) menggunakan logika timeout-dan-validasi yang sama.
- Jika setiap model di kedua lapis gagal, pekerja menyimpan transkrip mentah yang tidak terkonsolidasi ke penyimpanan dan memberi tahu teknisi on-call. Transkrip mentah tidak pernah dibuang, terlepas dari bagaimana konsolidasi diselesaikan.
- Catat model mana yang menyelesaikan setiap peristiwa (atau bahwa seluruh rantai gagal) sehingga Anda dapat mengukur tingkat penyelesaian Lapis 1 Anda sendiri dan menyusun ulang rantai nanti.
Kami tidak memublikasikan contoh kode yang dapat disalin-tempel dengan nama metode SDK, payload permintaan, atau bentuk respons spesifik untuk ketujuh penyedia ini, karena kumpulan bukti ini tidak berisi detail endpoint, autentikasi, dan payload yang terverifikasi untuk masing-masing, dan menciptakannya akan menghasilkan kode integrasi yang terlihat benar tetapi gagal secara diam-diam dalam produksi. Sebelum Anda mengimplementasikan alur ini, kerjakan daftar periksa verifikasi di bawah ini terhadap dokumentasi masing-masing penyedia.
Daftar periksa verifikasi sebelum Anda mengimplementasikan
- Konfirmasikan endpoint saat ini, format header autentikasi, dan bentuk isi permintaan untuk mode output terstruktur atau pemanggilan tool masing-masing penyedia langsung dari referensi API resmi mereka, bukan dari ringkasan pihak ketiga.
- Konfirmasikan pengecualian atau objek kesalahan apa yang dimunculkan oleh SDK masing-masing penyedia untuk 429, 500/502/503, dan timeout sisi klien, karena ini berbeda menurut SDK dan berubah di seluruh versi SDK.
- Konfirmasikan apakah pustaka klien masing-masing penyedia memiliki mekanisme percobaan ulang bawaan yang perlu Anda nonaktifkan, karena Anda menginginkan failover lintas penyedia dalam rantai ini, bukan percobaan ulang dalam pustaka terhadap model yang sama.
- Konfirmasikan validator skema JSON Anda berjalan pada setiap respons sebelum mencapai
persist_memory, termasuk respons yang mengembalikan HTTP 200. - Jika Anda merutekan melalui gateway multi-penyedia seperti TokenLab alih-alih memanggil setiap penyedia secara langsung, konfirmasikan format penerusan kesalahan gateway itu sendiri dalam dokumentasinya di tokenlab.sh/en/models sebelum berasumsi bahwa kode kesalahan spesifik penyedia disebarkan tanpa perubahan.
Catatan penanganan kesalahan, dipetakan ke kelas kegagalan nyata
| Kelas kesalahan | Penanganan |
|---|---|
| 429 limit rate | Segera pindah ke model berikutnya. Jangan mencoba ulang model yang sama dalam loop. Jika satu model membatasi rate berulang kali, tambahkan cooldown singkat sebelum dicoba lagi di panggilan mendatang. |
| 500/502/503 kesalahan server | Perlakukan sebagai sementara. Pindah ke model berikutnya. Jangan tambahkan backoff eksponensial di dalam rantai ini; failover ke penyedia yang berbeda lebih cepat daripada menunggu pemadaman satu penyedia. |
| Timeout | Batasi setiap percobaan (batas ilustratif 5-10 detik per panggilan; sesuaikan dengan panjang transkrip Anda). Saat timeout, pindah ke model berikutnya alih-alih memperpanjang waktu tunggu. |
| 4xx selain 429 | Biasanya bug format permintaan di sisi Anda. Catat dengan keras dan beri tahu manusia; jangan biarkan gagal secara diam-diam selamanya tanpa visibilitas. |
| 200 OK dengan isi cacat | Validasi terhadap skema JSON Anda sebelum menerima. Respons yang valid secara sintaksis dengan bentuk yang salah tetap merupakan kegagalan dan harus ditangkap oleh validasi, bukan hanya oleh status HTTP. |
Mengenai keberatan "apakah ini menyebabkan kelelahan limit rate": setiap model Lapis 1 berada di belakang penyedia yang berbeda, sehingga 429 pada satu model tidak mengonsumsi kuota penyedia lain. Rantai ini menyebarkan beban alih-alih memusatkannya. Skenario terburuk, lima percobaan Lapis 1 ditambah dua percobaan Lapis 2 adalah tujuh panggilan; dengan batas timeout 8 detik per percobaan, itu membatasi kasus terburuk sekitar satu menit, dan skenario itu mengharuskan setiap penyedia gagal secara bersamaan, yang merupakan kasus tepi langka yang dirancang untuk diatasi oleh desain ini, bukan jalur umum. Ini adalah batas berdasarkan timeout yang Anda konfigurasikan, bukan tolok ukur latensi produksi yang diukur; kami belum menjalankan rantai ini di bawah beban dan tidak melaporkan p50/p99 yang terukur.
Perbandingan biaya ilustratif di seluruh rantai fallback
Untuk menunjukkan mengapa merutekan sebagian besar volume melalui model murah itu penting, berikut adalah contoh kerja menggunakan tabel harga di atas. Asumsi: panggilan konsolidasi rata-rata mengirim transkrip 3.000 token sebagai input dan menghasilkan 400 token output terstruktur. Ini adalah asumsi ilustratif, bukan rata-rata terukur dari beban kerja pelanggan tertentu; ganti dengan jumlah token Anda sendiri.
| Model | Biaya per panggilan (asumsi di atas) |
|---|---|
| DeepSeek V4 Flash | $0,00034 |
| Qwen3.7 Plus | $0,00147 |
| GLM-5.2 | $0,00399 |
| Gemini 3.5 Flash | $0,00810 |
| Claude Sonnet 5 | $0,01000 |
| Claude Opus 4.8 | $0,02500 |
| GPT-5.5 | $0,02700 |
Perbedaannya nyata: merutekan 100% panggilan melalui GPT-5.5 memakan biaya sekitar 80x lebih mahal per panggilan daripada merutekan melalui DeepSeek V4 Flash, di bawah asumsi ini. Apa yang tidak dapat kami nyatakan tanpa data Anda sendiri adalah berapa fraksi lalu lintas Anda yang benar-benar terselesaikan di Lapis 1 dibandingkan meningkat ke Lapis 2, karena itu bergantung pada panjang transkrip, kompleksitas skema, dan keandalan penyedia pada hari Anda menjalankannya. Catat model mana yang menyelesaikan setiap peristiwa (langkah 7 dalam alur implementasi di atas) dan hitung biaya campuran Anda sendiri setelah beberapa ribu peristiwa alih-alih mengandalkan persentase pinjaman.
Keterbatasan
- Tidak ada tolok ukur tingkat kegagalan publik yang dapat direproduksi untuk rantai, beban kerja, atau tanggal yang tepat ini dalam kumpulan bukti ini. Lakukan instrumentasi pencatatan di runtime Anda sendiri sebelum mengutip angka spesifik.
- Tabel biaya di atas menggunakan jumlah token yang diasumsikan, bukan rata-rata panjang transkrip yang terukur. Hitung ulang dengan angka Anda sendiri menggunakan sumber tabel harga dan tanggal pengamatan.
- Harga model dan jendela konteks berubah. Konfirmasikan nilai saat ini di direktori model TokenLab sebelum menyelesaikan urutan rantai untuk produksi.
- Rantai fallback mengurangi risiko titik kegagalan tunggal; itu tidak menjamin nol kehilangan data. Selalu simpan transkrip mentah secara terpisah dari output konsolidasi terstruktur.
- Angka latensi dan kelelahan limit rate dalam artikel ini adalah perkiraan berdasarkan timeout yang dapat dikonfigurasi, bukan tolok ukur produksi yang terukur. Kami belum menjalankan rantai ini di bawah beban dalam kumpulan bukti ini.
- Artikel ini sengaja tidak menyertakan kode permintaan yang dapat disalin-tempel, karena bukti endpoint, header autentikasi, dan payload yang tepat untuk ketujuh penyedia ini tidak tersedia untuk diverifikasi pada saat penulisan. Gunakan daftar periksa verifikasi dan dokumen resmi masing-masing penyedia sebelum mengimplementasikan.
Daftar periksa implementasi
| Praktik | Mengapa itu penting |
|---|---|
| Validasi skema, bukan hanya status HTTP | Respons 200 dengan JSON cacat atau pemanggilan tool yang hilang tetap merupakan kegagalan yang harus ditangkap oleh logika percobaan ulang Anda. |
| Batasi timeout per percobaan | Batasi waktu dinding kasus terburuk agar satu penyedia yang lambat tidak menghambat seluruh pekerjaan latar belakang. |
| Failover lintas penyedia, bukan dalam satu penyedia | 429 atau 503 pada satu penyedia harus segera merutekan ke penyedia yang berbeda alih-alih mencoba ulang yang sama. |
| Catat model mana yang menyelesaikan setiap peristiwa | Beginilah cara Anda mengukur tingkat penyelesaian Lapis 1 Anda sendiri dan menyusun ulang rantai seiring pergeseran harga dan keandalan. |
| Jangan pernah membuang transkrip mentah | Bahkan pada kegagalan rantai penuh, simpan percakapan mentah. Ringkasan terstruktur yang gagal dapat dipulihkan; transkrip yang dihapus tidak bisa. |
| Beri peringatan pada kesalahan 4xx selain 429/503 | Ini biasanya menunjukkan bug skema atau permintaan di sisi Anda, bukan masalah penyedia sementara, dan tidak boleh dicoba ulang secara diam-diam selamanya. |
| Verifikasi tipe kesalahan SDK per penyedia sebelum menyebarkan | Kelas pengecualian untuk 429, 5xx, dan timeout berbeda di seluruh SDK penyedia dan berubah antar versi SDK; periksa dokumen saat ini alih-alih berasumsi. |
Untuk keputusan perutean tingkat penyedia di luar model individu, perbandingan OpenRouter mencakup bagaimana perutean multi-penyedia mengubah perilaku limit rate dan failover.
FAQ
Apa itu konsolidasi memori agen AI?
Proses latar belakang yang mengubah transkrip percakapan mentah menjadi memori terstruktur dan tahan lama (fakta, preferensi, keputusan) yang ditulis ke penyimpanan jangka panjang, biasanya melalui pemanggilan tool paksa atau penyelesaian mode JSON di akhir sesi.
Bagaimana cara mengimplementasikan konsolidasi memori latar belakang asinkron tanpa memblokir chat?
Picu saat sesi ditutup atau timeout idle sebagai pekerjaan pekerja latar belakang, terpisah dari jalur respons chat. Pekerja menulis ke penyimpanan memori Anda saat selesai; pesan pengguna berikutnya tidak menunggu itu. Ini juga yang membuat latensi percobaan ulang multi-model dapat diterima, karena terjadi di luar jalur kritis.
Apakah rantai percobaan ulang 5-7 model akan menyebabkan masalah latensi atau limit rate?
Risiko latensi dibatasi oleh timeout per percobaan Anda dan diserap dengan menjalankan konsolidasi secara asinkron. Risiko limit rate dimitigasi karena rantai melakukan failover di seluruh penyedia yang berbeda alih-alih mencoba ulang satu penyedia berulang kali, sehingga 429 pada satu model tidak menghantam atau menghabiskan kuota penyedia lain. Ini adalah mitigasi arsitektural, bukan angka latensi yang terukur; kami belum mematok rantai ini di bawah beban produksi.
Model mana yang harus menangani konsolidasi memori secara default?
Mulailah dengan model andal termurah untuk volume Anda, seperti DeepSeek V4 Flash, dan rantai empat atau lima model di seluruh penyedia berbeda di belakangnya sebagai Lapis 1. Cadangkan Claude Sonnet 5 dan Claude Opus 4.8 sebagai eskalasi Lapis 2 saja. Periksa harga saat ini di direktori model TokenLab sebelum menyelesaikan urutan.
Apa yang terjadi jika setiap model dalam rantai fallback gagal?
Simpan transkrip mentah yang tidak terkonsolidasi alih-alih membuangnya, beri tahu manusia, dan periksa apakah transkrip itu sendiri (panjang, format, penyandian) memicu kegagalan di seluruh penyedia, karena penyebab bersama lebih mungkin terjadi daripada tujuh pemadaman independen.
Bagaimana saya tahu jika ini benar-benar mengurangi biaya saya?
Catat lapisan mana yang menyelesaikan setiap peristiwa konsolidasi dan hitung biaya campuran dari data Anda sendiri menggunakan tabel harga per model di atas. Jangan mengandalkan persentase pinjaman; tingkat penyelesaian Anda bergantung pada panjang transkrip, keketatan skema, dan keandalan penyedia Anda.
Mengapa artikel ini tidak menyertakan kode API yang berfungsi?
Karena kumpulan bukti ini tidak berisi detail endpoint, autentikasi, dan payload saat ini yang terverifikasi untuk ketujuh penyedia dalam rantai tersebut, dan memublikasikan kode permintaan yang terlihat masuk akal tetapi tidak terverifikasi akan lebih buruk daripada tidak ada kode sama sekali. Gunakan daftar periksa verifikasi di atas terhadap referensi API resmi masing-masing penyedia sebelum Anda menulis integrasi Anda.
Memulai
Jika Anda membangun memori agen yang tidak mampu kehilangan konteks secara diam-diam, mulailah dengan TokenLab untuk membandingkan harga saat ini dan merutekan lalu lintas konsolidasi di seluruh model dalam rantai fallback ini melalui satu kunci API, alih-alih mengelola kredensial dan limit rate yang terpisah per penyedia.
Sumber
Harga diamati pada 2026-07-07
- fal PixVerse V6 model pageDiamati pada 2026-07-09
- fal FLUX.2 model pageDiamati pada 2026-07-09
- TokenLab model directoryDiamati pada 2026-07-07