Một người dùng kết thúc phiên làm việc 30 phút với agent của bạn. Họ đã chia sẻ các yêu cầu, nêu rõ sở thích và đưa ra quyết định. Sau đó, họ bắt đầu một phiên mới và không có thông tin nào được lưu lại. Điều thường bị hỏng không phải là khả năng suy luận của agent, mà là quá trình hợp nhất bộ nhớ của AI agent: bước chạy nền giúp chuyển đổi bản ghi thô thành bộ nhớ dài hạn có cấu trúc. Bước đó là một lệnh gọi API đơn lẻ tới một mô hình duy nhất, và các lệnh gọi API đơn lẻ thường thất bại. Giới hạn tốc độ (rate limit), thời gian chờ (timeout) và đầu ra công cụ bị lỗi định dạng đều tạo ra cùng một triệu chứng: mất bộ nhớ âm thầm mà không hiển thị lỗi cho người dùng.
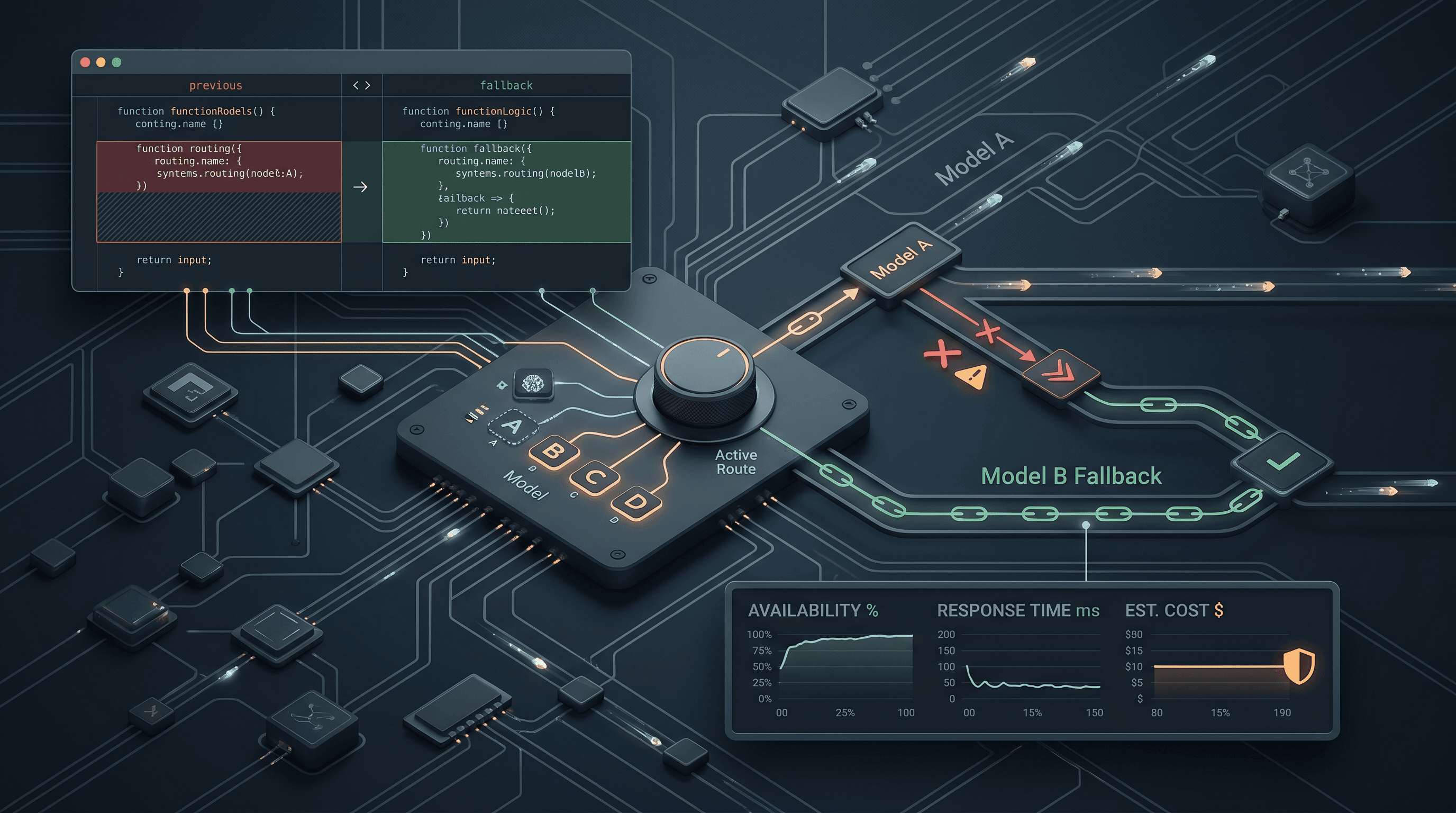
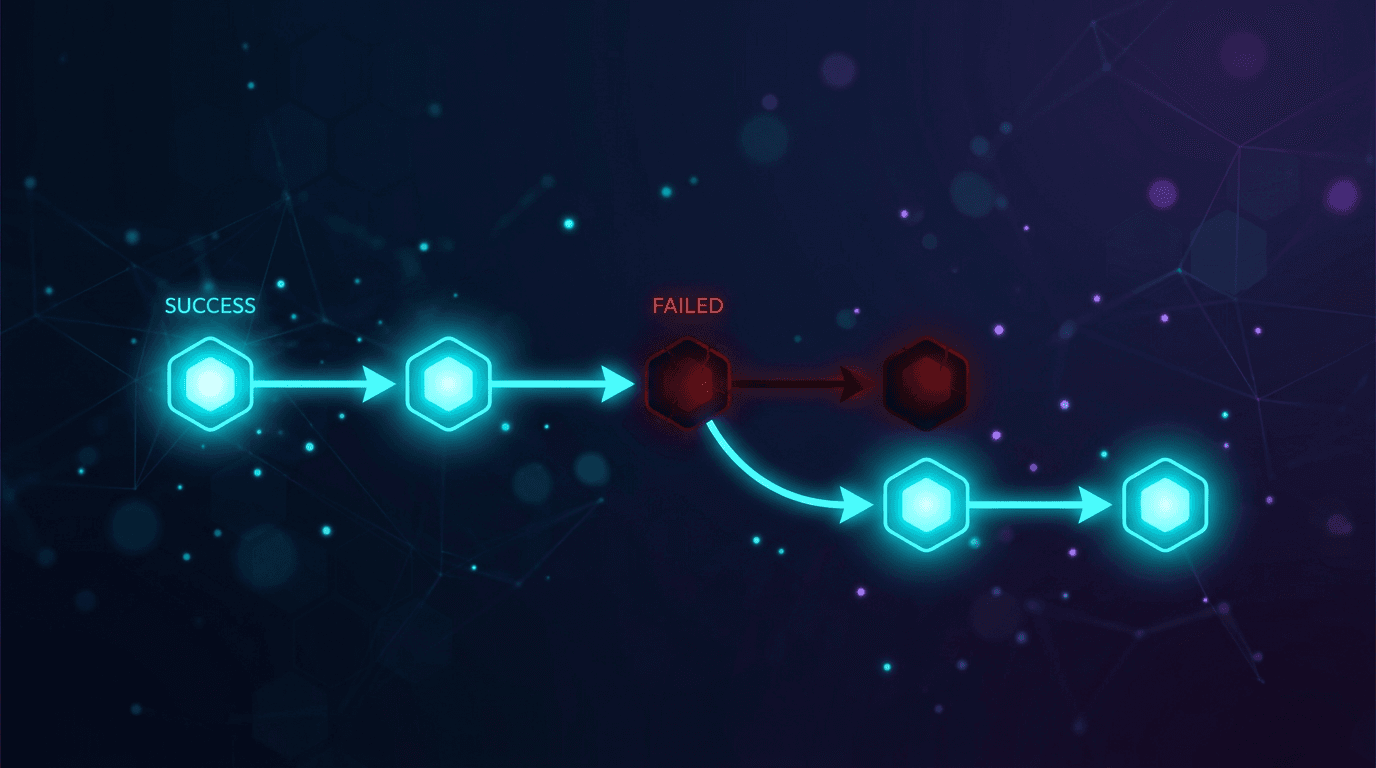
Giải pháp trong bài viết này mang tính kiến trúc, không phải là một câu lệnh (prompt) tốt hơn: hãy chạy quá trình hợp nhất thông qua một chuỗi các mô hình được sắp xếp thay vì chỉ một mô hình, để việc thất bại ở bất kỳ nhà cung cấp nào cũng không làm xóa mất nội dung cuộc trò chuyện.
Nếu bạn đang xây dựng bề mặt sản phẩm xung quanh thay vì chỉ là hệ thống con bộ nhớ, hãy kết hợp trang này với hướng dẫn chatbot một khóa API và hướng dẫn giới hạn tốc độ API AI. Nếu bạn đang so sánh các nhà cung cấp thay vì từng mô hình riêng lẻ, hãy đọc bài so sánh OpenRouter cùng với bài viết này.
Các điểm chính cần lưu ý
- Hợp nhất bộ nhớ là một tác vụ đầu ra có cấu trúc, hẹp (gọi công cụ hoặc ép buộc JSON), và các lệnh gọi đầu ra có cấu trúc có nhiều chế độ thất bại hơn so với trò chuyện tự do: vi phạm lược đồ (schema), cắt bớt dữ liệu, giới hạn tốc độ, thời gian chờ.
- Một mô hình duy nhất xử lý việc hợp nhất là một điểm lỗi duy nhất. Hãy coi việc hợp nhất là một vấn đề về độ tin cậy với chuỗi dự phòng, không phải là vấn đề về kỹ thuật prompt.
- Chuỗi hai lớp hoạt động tốt trong thực tế: Lớp 1 là một chuỗi các mô hình chi phí thấp (DeepSeek V4 Flash, GLM-5.2, Qwen3.7 Plus, Gemini 3.5 Flash, GPT-5.5) tự động chuyển đổi cho nhau khi có bất kỳ lỗi nào. Lớp 2 sẽ leo thang lên Claude Sonnet 5, sau đó là Claude Opus 4.8, chỉ khi tất cả các mô hình Lớp 1 đều thất bại.
- Bài viết này không có tỷ lệ thất bại hoặc tỷ lệ giảm chi phí được công bố, có thể tái lập cho thời gian chạy chính xác này. Các phép tính giá dưới đây chỉ mang tính minh họa. Hãy đo lường khối lượng công việc của riêng bạn trước khi trích dẫn một con số.
- Vì chuỗi này chuyển đổi dự phòng qua các nhà cung cấp độc lập thay vì thử lại một nhà cung cấp nhiều lần, nó không tập trung tải vào một giới hạn tốc độ duy nhất, và vì việc hợp nhất chạy như một tác vụ nền bất đồng bộ, độ trễ khi thử lại không làm chặn lượt trò chuyện của người dùng.
Hợp nhất bộ nhớ AI agent là gì?
Hợp nhất bộ nhớ là quá trình chuyển đổi bản ghi cuộc trò chuyện thô thành các sự kiện có cấu trúc, bền vững: sở thích người dùng, quyết định, trạng thái dự án, các thực thể được đề cập. Nó khác với cửa sổ ngữ cảnh hoạt động của agent, nơi chứa các tin nhắn của phiên hiện tại. Việc hợp nhất thường chạy mỗi phiên một lần (khi đóng, khi hết thời gian chờ nhàn rỗi, hoặc trên một cửa sổ cuộn) và ghi đầu ra của nó vào cơ sở dữ liệu, vector store hoặc dịch vụ bộ nhớ thay vì quay lại cuộc trò chuyện.
Vì đầu ra phải khớp với một lược đồ (để mã truy xuất hạ nguồn có thể sử dụng), việc hợp nhất hầu như luôn được triển khai dưới dạng lệnh gọi công cụ bắt buộc hoặc hoàn thành ở chế độ JSON, không phải là câu trả lời trò chuyện thông thường. Đó là chi tiết khiến nó trở nên mong manh: một mô hình có thể duy trì một cuộc trò chuyện hoàn hảo nhưng vẫn thất bại ở bước hợp nhất bằng cách trả về văn bản thay vì lệnh gọi công cụ, cắt bớt JSON trên một bản ghi dài hoặc tự tạo ra một trường mà lược đồ của bạn không có.
Tại sao việc hợp nhất bằng một mô hình duy nhất lại thất bại
Các lệnh gọi đầu ra có cấu trúc có nhiều chế độ thất bại hơn so với hoàn thành trò chuyện bình thường:
- Mô hình bỏ qua lược đồ công cụ và trả về văn bản thay vì lệnh gọi công cụ.
- Nhà cung cấp trả về giới hạn tốc độ (429) hoặc lỗi máy chủ (500/502/503) trong thời gian lưu lượng truy cập tăng đột biến.
- Yêu cầu hết thời gian chờ, thường xảy ra trên các bản ghi dài hơn cần nhiều token để tóm tắt.
- Mô hình trả về JSON hợp lệ với tên trường hoặc kiểu dữ liệu không khớp với lược đồ của bạn.
Bất kỳ lỗi nào trong số này đều biến một cuộc trò chuyện hoàn chỉnh thành một khoảng trống bộ nhớ âm thầm. Không có lỗi nào được hiển thị cho người dùng. Họ sẽ nhận ra sau đó, khi agent "quên" điều gì đó, và đến lúc đó bản ghi thô có thể đã mất nếu bạn không lưu trữ nó riêng biệt.
Chúng tôi chưa công bố chuẩn tỷ lệ thất bại có kiểm soát cho thời gian chạy, khối lượng công việc hoặc ngày cụ thể này, vì vậy chúng tôi sẽ không nêu lại một tỷ lệ phần trăm cụ thể ở đây. Điều có thể xác minh là cơ chế: bốn chế độ thất bại cụ thể, được nêu tên ở trên, tất cả đều bị loại bỏ như các điểm lỗi duy nhất khi bạn tạo chuỗi các mô hình thay vì gọi một mô hình.
Giá mô hình cho chuỗi dự phòng
Bảng dưới đây liệt kê giá TokenLab hiện tại cho các mô hình được sử dụng trong chuỗi dự phòng được mô tả trong bài viết này. Đây là ảnh chụp nhanh giá trực tiếp của TokenLab, khác với bất kỳ tài liệu nào do nhà cung cấp công bố. Hãy xác minh những giá này trước khi chốt đơn hàng, vì giá mỗi token thay đổi theo thời gian.
| Mô hình | Cửa sổ ngữ cảnh | Đầu vào $/MTok | Đầu ra $/MTok | Nguồn | Ngày quan sát |
|---|---|---|---|---|---|
| DeepSeek V4 Flash | 1,048,576 | $0.09 | $0.18 | Ảnh chụp nhanh giá/mô hình trực tiếp TokenLab | 2026-07-09 |
| GLM-5.2 | 1,048,576 | $0.93 | $3.00 | Ảnh chụp nhanh giá/mô hình trực tiếp TokenLab | 2026-07-09 |
| Qwen3.7 Plus | 1,000,000 | $0.32 | $1.28 | Ảnh chụp nhanh giá/mô hình trực tiếp TokenLab | 2026-07-09 |
| Gemini 3.5 Flash | 1,048,576 | $1.50 | $9.00 | Ảnh chụp nhanh giá/mô hình trực tiếp TokenLab | 2026-07-09 |
| GPT-5.5 | 1,050,000 | $5.00 | $30.00 | Ảnh chụp nhanh giá/mô hình trực tiếp TokenLab | 2026-07-09 |
| Claude Sonnet 5 | 1,000,000 | $2.00 | $10.00 | Ảnh chụp nhanh giá/mô hình trực tiếp TokenLab | 2026-07-09 |
| Claude Opus 4.8 | 1,000,000 | $5.00 | $25.00 | Ảnh chụp nhanh giá/mô hình trực tiếp TokenLab | 2026-07-09 |
Để biết giới hạn tốc độ trực tiếp, giá mới nhất và bảng xếp hạng độ tin cậy, hãy kiểm tra danh mục mô hình TokenLab và bảng xếp hạng mô hình trước khi hoàn thiện thứ tự chuỗi của bạn.
Nếu bạn đang định tuyến lưu lượng hợp nhất bộ nhớ trong môi trường sản xuất, hãy bắt đầu với TokenLab để tiếp cận tất cả bảy mô hình này thông qua một khóa API duy nhất thay vì quản lý thông tin xác thực, giới hạn tốc độ và định dạng lỗi riêng biệt cho từng nhà cung cấp.
Kiến trúc dự phòng hai lớp
Lớp 1: giá rẻ, khối lượng lớn, đa dạng nhà cung cấp
Lớp này chạy trên mọi sự kiện hợp nhất. Hãy tạo chuỗi các mô hình trên ít nhất ba nhà cung cấp khác nhau, theo thứ tự này:
- DeepSeek V4 Flash
- GLM-5.2
- Qwen3.7 Plus
- Gemini 3.5 Flash
- GPT-5.5
Khi có bất kỳ lỗi gọi công cụ, vi phạm lược đồ, thời gian chờ hoặc phản hồi 4xx/5xx nào, hãy chuyển ngay sang mô hình tiếp theo trong danh sách. Không thử lại cùng một mô hình trong Lớp 1; giới hạn tốc độ hoặc phản hồi bị lỗi định dạng có khả năng lặp lại cao hơn là được giải quyết khi thử lại ngay lập tức.
Lớp 2: leo thang cho các trường hợp biên thực sự
Nếu mọi mô hình Lớp 1 đều thất bại, hãy leo thang lên một mô hình mạnh hơn thay vì quay lại Lớp 1:
- Claude Sonnet 5
- Claude Opus 4.8 (dự phòng cuối cùng)
Lớp 2 sẽ rất hiếm khi được sử dụng. Nếu bạn thấy các lần leo thang Lớp 2 thường xuyên trong nhật ký của mình, đó là tín hiệu để kiểm tra thứ tự Lớp 1, độ nghiêm ngặt của lược đồ hoặc độ dài bản ghi của bạn, không phải là lý do để biến Lớp 2 thành đường dẫn mặc định.
Cách triển khai hợp nhất bộ nhớ nền bất đồng bộ
Việc hợp nhất không bao giờ được chặn tin nhắn tiếp theo của người dùng. Hãy chạy nó như một tác vụ nền được kích hoạt khi đóng phiên hoặc hết thời gian chờ nhàn rỗi, ghi vào kho bộ nhớ của bạn khi hoàn tất, không phải ghi trực tiếp vào đường dẫn phản hồi trò chuyện. Việc tách biệt này cũng là điều làm cho độ trễ trường hợp xấu nhất của chuỗi đa mô hình trở nên chấp nhận được: vài giây thử lại trong một worker nền không ảnh hưởng đến lượt tương tác của người dùng.
Luồng điều khiển, được mô tả không cần mã, là:
- Khi đóng phiên hoặc hết thời gian chờ nhàn rỗi, hãy xếp hàng một tác vụ nền với bản ghi đầy đủ.
- Worker cố gắng hợp nhất với mô hình đầu tiên trong danh sách Lớp 1, với thời gian chờ giới hạn cho mỗi lần thử.
- Khi hết thời gian chờ, 429 hoặc 5xx, worker chuyển sang mô hình tiếp theo trong danh sách ngay lập tức, không thử lại tại chỗ với cùng một mô hình.
- Khi có phản hồi 200, worker xác thực tải trọng (payload) dựa trên lược đồ JSON của bạn trước khi chấp nhận nó. Một phản hồi vượt qua kiểm tra trạng thái HTTP nhưng thất bại trong việc xác thực lược đồ sẽ được xử lý giống như lỗi mạng: ghi nhật ký và chuyển sang mô hình tiếp theo.
- Nếu mọi mô hình Lớp 1 đều thất bại, worker leo thang lên Lớp 2 (Claude Sonnet 5, sau đó là Claude Opus 4.8) sử dụng cùng logic thời gian chờ và xác thực.
- Nếu mọi mô hình trong cả hai lớp đều thất bại, worker lưu trữ bản ghi thô, chưa hợp nhất vào bộ nhớ và cảnh báo cho kỹ sư trực. Bản ghi thô không bao giờ bị loại bỏ, bất kể việc hợp nhất được giải quyết như thế nào.
- Ghi nhật ký mô hình nào đã giải quyết từng sự kiện (hoặc toàn bộ chuỗi đã thất bại) để bạn có thể đo lường tỷ lệ giải quyết Lớp 1 của riêng mình và sắp xếp lại chuỗi sau này.
Chúng tôi không xuất bản mẫu mã có thể sao chép-dán với các tên phương thức SDK, tải trọng yêu cầu hoặc hình dạng phản hồi cụ thể cho bảy nhà cung cấp này, vì tập bằng chứng này không chứa các chi tiết điểm cuối, xác thực và tải trọng đã được xác minh cho từng nhà cung cấp, và việc tự tạo ra chúng sẽ tạo ra mã tích hợp trông có vẻ đúng nhưng lại thất bại âm thầm trong môi trường sản xuất. Trước khi bạn triển khai luồng này, hãy thực hiện danh sách kiểm tra xác minh bên dưới dựa trên tài liệu của từng nhà cung cấp.
Danh sách kiểm tra xác minh trước khi triển khai
- Xác nhận điểm cuối hiện tại, định dạng tiêu đề xác thực và hình dạng nội dung yêu cầu cho chế độ đầu ra có cấu trúc hoặc gọi công cụ của từng nhà cung cấp trực tiếp từ tài liệu tham khảo API chính thức của họ, không phải từ tóm tắt của bên thứ ba.
- Xác nhận đối tượng ngoại lệ hoặc lỗi nào mà SDK của từng nhà cung cấp đưa ra cho 429, 500/502/503 và thời gian chờ phía máy khách, vì những lỗi này khác nhau theo SDK và thay đổi qua các phiên bản SDK.
- Xác nhận xem thư viện máy khách của từng nhà cung cấp có cơ chế thử lại tích hợp mà bạn cần vô hiệu hóa hay không, vì bạn muốn chuyển đổi dự phòng chéo giữa các nhà cung cấp trong chuỗi này, không phải thử lại trong thư viện với cùng một mô hình.
- Xác nhận trình xác thực lược đồ JSON của bạn chạy trên mọi phản hồi trước khi nó đến
persist_memory, bao gồm cả các phản hồi trả về HTTP 200. - Nếu bạn định tuyến qua cổng đa nhà cung cấp như TokenLab thay vì gọi trực tiếp từng nhà cung cấp, hãy xác nhận định dạng chuyển tiếp lỗi của chính cổng đó trong tài liệu tại tokenlab.sh/en/models trước khi giả định rằng các mã lỗi cụ thể của nhà cung cấp được truyền đi mà không thay đổi.
Ghi chú xử lý lỗi, ánh xạ tới các lớp lỗi thực tế
| Lớp lỗi | Xử lý |
|---|---|
| 429 giới hạn tốc độ | Chuyển sang mô hình tiếp theo ngay lập tức. Không thử lại cùng một mô hình trong vòng lặp. Nếu một mô hình liên tục bị giới hạn tốc độ, hãy thêm thời gian chờ ngắn trước khi thử lại trong các lệnh gọi tương lai. |
| 500/502/503 lỗi máy chủ | Coi là tạm thời. Chuyển sang mô hình tiếp theo. Không thêm cơ chế backoff lũy thừa bên trong chuỗi này; chuyển đổi dự phòng sang nhà cung cấp khác nhanh hơn là chờ đợi sự cố của một nhà cung cấp. |
| Thời gian chờ (Timeout) | Giới hạn mỗi lần thử (giới hạn minh họa 5-10 giây mỗi lần gọi; điều chỉnh theo độ dài bản ghi của bạn). Khi hết thời gian chờ, chuyển sang mô hình tiếp theo thay vì kéo dài thời gian chờ. |
| 4xx khác ngoài 429 | Thường là lỗi định dạng yêu cầu từ phía bạn. Ghi nhật ký rõ ràng và cảnh báo cho con người; đừng để nó thất bại âm thầm mãi mãi mà không có khả năng hiển thị. |
| 200 OK với nội dung bị lỗi | Xác thực dựa trên lược đồ JSON của bạn trước khi chấp nhận. Một phản hồi hợp lệ về cú pháp nhưng sai hình dạng vẫn là một thất bại và phải được bắt bởi xác thực, không chỉ bởi trạng thái HTTP. |
Về phản đối "điều này có gây cạn kiệt giới hạn tốc độ không": mỗi mô hình Lớp 1 nằm sau một nhà cung cấp khác nhau, vì vậy 429 trên một mô hình không tiêu tốn hạn ngạch của nhà cung cấp khác. Chuỗi này phân tán tải thay vì tập trung nó. Trường hợp xấu nhất, năm lần thử Lớp 1 cộng với hai lần thử Lớp 2 là bảy lần gọi; với giới hạn thời gian chờ 8 giây mỗi lần thử, điều đó giới hạn trường hợp xấu nhất trong khoảng một phút, và kịch bản đó đòi hỏi mọi nhà cung cấp phải thất bại đồng thời, đó là trường hợp biên hiếm gặp mà thiết kế này được xây dựng để tồn tại, không phải là đường dẫn phổ biến. Đây là giới hạn dựa trên thời gian chờ bạn định cấu hình, không phải là điểm chuẩn độ trễ sản xuất được đo lường; chúng tôi chưa chạy chuỗi này dưới tải và không báo cáo p50/p99 được đo lường.
So sánh chi phí minh họa trên chuỗi dự phòng
Để cho thấy tại sao việc định tuyến hầu hết lưu lượng qua các mô hình giá rẻ lại quan trọng, đây là một ví dụ thực tế sử dụng bảng giá ở trên. Giả định: một lệnh gọi hợp nhất trung bình gửi bản ghi 3.000 token làm đầu vào và tạo ra 400 token đầu ra có cấu trúc. Đây là một giả định minh họa, không phải mức trung bình được đo lường từ bất kỳ khối lượng công việc khách hàng cụ thể nào; hãy thay thế bằng số lượng token của riêng bạn.
| Mô hình | Chi phí mỗi lần gọi (giả định trên) |
|---|---|
| DeepSeek V4 Flash | $0.00034 |
| Qwen3.7 Plus | $0.00147 |
| GLM-5.2 | $0.00399 |
| Gemini 3.5 Flash | $0.00810 |
| Claude Sonnet 5 | $0.01000 |
| Claude Opus 4.8 | $0.02500 |
| GPT-5.5 | $0.02700 |
Sự chênh lệch là có thật: định tuyến 100% các lệnh gọi qua GPT-5.5 tốn kém gấp khoảng 80 lần mỗi lệnh gọi so với định tuyến qua DeepSeek V4 Flash, theo giả định này. Điều chúng tôi không thể nêu rõ nếu không có dữ liệu của riêng bạn là bao nhiêu phần trăm lưu lượng truy cập của bạn thực sự được giải quyết ở Lớp 1 so với leo thang lên Lớp 2, vì điều đó phụ thuộc vào độ dài bản ghi, độ phức tạp của lược đồ và độ tin cậy của nhà cung cấp vào ngày bạn chạy nó. Hãy ghi nhật ký mô hình nào giải quyết từng sự kiện (bước 7 trong luồng triển khai ở trên) và tính toán chi phí hỗn hợp của riêng bạn sau vài nghìn sự kiện thay vì dựa vào một tỷ lệ phần trăm vay mượn.
Hạn chế
- Không có chuẩn tỷ lệ thất bại công khai, có thể tái lập cho chuỗi, khối lượng công việc hoặc ngày chính xác này trong tập bằng chứng này. Hãy thiết lập ghi nhật ký trong thời gian chạy của riêng bạn trước khi trích dẫn một con số cụ thể.
- Bảng chi phí ở trên sử dụng số lượng token giả định, không phải độ dài bản ghi trung bình được đo lường. Hãy tính toán lại với các con số của riêng bạn bằng cách sử dụng nguồn và ngày quan sát của bảng giá.
- Giá mô hình và cửa sổ ngữ cảnh thay đổi. Xác nhận các giá trị hiện tại trên danh mục mô hình TokenLab trước khi hoàn thiện thứ tự chuỗi cho sản xuất.
- Chuỗi dự phòng làm giảm rủi ro điểm lỗi duy nhất; nó không đảm bảo không mất dữ liệu. Luôn lưu trữ bản ghi thô tách biệt với đầu ra hợp nhất có cấu trúc.
- Các số liệu về độ trễ và cạn kiệt giới hạn tốc độ trong bài viết này là ước tính dựa trên thời gian chờ có thể định cấu hình, không phải điểm chuẩn sản xuất được đo lường. Chúng tôi chưa chạy chuỗi này dưới tải trong tập bằng chứng này.
- Bài viết này cố tình không bao gồm mã yêu cầu có thể sao chép-dán, vì chi tiết điểm cuối, tiêu đề xác thực và tải trọng chính xác cho bảy nhà cung cấp này không có sẵn để xác minh tại thời điểm viết. Sử dụng danh sách kiểm tra xác minh và tài liệu chính thức của từng nhà cung cấp trước khi triển khai.
Danh sách kiểm tra triển khai
| Thực hành | Tại sao nó quan trọng |
|---|---|
| Xác thực lược đồ, không chỉ trạng thái HTTP | Phản hồi 200 với JSON bị lỗi hoặc thiếu lệnh gọi công cụ vẫn là một thất bại mà logic thử lại của bạn phải bắt được. |
| Giới hạn thời gian chờ mỗi lần thử | Giới hạn thời gian thực tế trường hợp xấu nhất để một nhà cung cấp chậm không làm đình trệ toàn bộ tác vụ nền. |
| Chuyển đổi dự phòng giữa các nhà cung cấp, không phải trong một nhà cung cấp | 429 hoặc 503 trên một nhà cung cấp nên định tuyến sang nhà cung cấp khác ngay lập tức thay vì thử lại cùng một nhà cung cấp. |
| Ghi nhật ký mô hình nào đã giải quyết từng sự kiện | Đây là cách bạn đo lường tỷ lệ giải quyết Lớp 1 của riêng mình và sắp xếp lại chuỗi khi giá cả và độ tin cậy thay đổi. |
| Không bao giờ bỏ bản ghi thô | Ngay cả khi toàn bộ chuỗi thất bại, hãy lưu trữ cuộc trò chuyện thô. Một bản tóm tắt có cấu trúc bị lỗi có thể khôi phục được; một bản ghi đã xóa thì không. |
| Cảnh báo về các lỗi 4xx không phải 429/503 | Những lỗi này thường chỉ ra lỗi lược đồ hoặc yêu cầu từ phía bạn, không phải vấn đề tạm thời của nhà cung cấp, và không nên được thử lại âm thầm mãi mãi. |
| Xác minh các loại lỗi SDK theo nhà cung cấp trước khi triển khai | Các lớp ngoại lệ cho 429, 5xx và thời gian chờ khác nhau giữa các SDK nhà cung cấp và thay đổi giữa các phiên bản SDK; hãy kiểm tra tài liệu hiện tại thay vì giả định. |
Đối với các quyết định định tuyến cấp nhà cung cấp ngoài các mô hình riêng lẻ, bài so sánh OpenRouter đề cập đến cách định tuyến đa nhà cung cấp thay đổi hành vi giới hạn tốc độ và chuyển đổi dự phòng.
Câu hỏi thường gặp
Hợp nhất bộ nhớ AI agent là gì?
Quá trình chạy nền chuyển đổi bản ghi cuộc trò chuyện thô thành bộ nhớ có cấu trúc, bền vững (sự kiện, sở thích, quyết định) được ghi vào bộ nhớ dài hạn, thường thông qua lệnh gọi công cụ bắt buộc hoặc hoàn thành ở chế độ JSON khi kết thúc phiên.
Làm cách nào để triển khai hợp nhất bộ nhớ nền bất đồng bộ mà không chặn trò chuyện?
Kích hoạt nó khi đóng phiên hoặc hết thời gian chờ nhàn rỗi như một tác vụ worker nền, tách biệt với đường dẫn phản hồi trò chuyện. Worker ghi vào kho bộ nhớ của bạn khi hoàn tất; tin nhắn tiếp theo của người dùng không chờ đợi nó. Đây cũng là điều làm cho độ trễ thử lại đa mô hình trở nên chấp nhận được, vì nó xảy ra ngoài đường dẫn quan trọng.
Chuỗi thử lại 5-7 mô hình có gây ra vấn đề về độ trễ hoặc giới hạn tốc độ không?
Rủi ro độ trễ bị giới hạn bởi thời gian chờ mỗi lần thử của bạn và được hấp thụ bằng cách chạy hợp nhất bất đồng bộ. Rủi ro giới hạn tốc độ được giảm thiểu vì chuỗi chuyển đổi dự phòng giữa các nhà cung cấp khác nhau thay vì thử lại một nhà cung cấp nhiều lần, vì vậy 429 trên một mô hình không làm ảnh hưởng hoặc cạn kiệt hạn ngạch của nhà cung cấp khác. Đây là các biện pháp giảm thiểu kiến trúc, không phải con số độ trễ được đo lường; chúng tôi chưa đo lường chuỗi này dưới tải sản xuất.
Mô hình nào nên xử lý hợp nhất bộ nhớ theo mặc định?
Bắt đầu với mô hình đáng tin cậy rẻ nhất cho khối lượng của bạn, chẳng hạn như DeepSeek V4 Flash, và tạo chuỗi bốn hoặc năm mô hình trên các nhà cung cấp khác nhau phía sau nó làm Lớp 1. Chỉ dành Claude Sonnet 5 và Claude Opus 4.8 làm leo thang Lớp 2. Kiểm tra giá hiện tại trên danh mục mô hình TokenLab trước khi hoàn thiện thứ tự.
Điều gì xảy ra nếu mọi mô hình trong chuỗi dự phòng đều thất bại?
Lưu trữ bản ghi thô chưa hợp nhất thay vì loại bỏ nó, cảnh báo cho con người và kiểm tra xem bản thân bản ghi (độ dài, định dạng, mã hóa) có đang kích hoạt lỗi trên mọi nhà cung cấp hay không, vì nguyên nhân chung có khả năng xảy ra cao hơn bảy sự cố độc lập.
Làm sao tôi biết liệu điều này có thực sự giảm chi phí của tôi không?
Ghi nhật ký lớp nào giải quyết từng sự kiện hợp nhất và tính toán chi phí hỗn hợp từ dữ liệu của riêng bạn bằng bảng giá mỗi mô hình ở trên. Đừng dựa vào tỷ lệ phần trăm vay mượn; tỷ lệ giải quyết của bạn phụ thuộc vào độ dài bản ghi, độ nghiêm ngặt của lược đồ và độ tin cậy của nhà cung cấp.
Tại sao bài viết này không bao gồm mã API hoạt động?
Vì tập bằng chứng này không chứa các chi tiết điểm cuối, xác thực và tải trọng hiện tại đã được xác minh cho tất cả bảy nhà cung cấp trong chuỗi, và việc xuất bản mã yêu cầu trông có vẻ hợp lý nhưng chưa được xác minh sẽ còn tệ hơn là không có mã nào cả. Sử dụng danh sách kiểm tra xác minh ở trên dựa trên tài liệu tham khảo API chính thức của từng nhà cung cấp trước khi bạn viết mã tích hợp.
Bắt đầu
Nếu bạn đang xây dựng bộ nhớ agent mà không thể chấp nhận việc mất ngữ cảnh âm thầm, hãy bắt đầu với TokenLab để so sánh giá hiện tại và định tuyến lưu lượng hợp nhất qua các mô hình trong chuỗi dự phòng này thông qua một khóa API duy nhất, thay vì quản lý thông tin xác thực và giới hạn tốc độ riêng biệt cho từng nhà cung cấp.
Nguồn
Giá quan sát ngày 2026-07-07
- fal PixVerse V6 model pageQuan sát ngày 2026-07-09
- fal FLUX.2 model pageQuan sát ngày 2026-07-09
- TokenLab model directoryQuan sát ngày 2026-07-07