使用者結束了與您 Agent 的 30 分鐘對話。他們分享了需求、陳述了偏好並做出了決定。然後他們開始了新的對話,但之前的內容卻完全沒有保留下來。通常出問題的不是 Agent 的推理能力,而是 AI Agent 記憶整合 (memory consolidation):即將原始對話記錄轉換為結構化長期記憶的後台步驟。該步驟是對單一模型的一次 API 呼叫,而單一 API 呼叫是有可能失敗的。速率限制 (rate limits)、逾時 (timeouts) 和格式錯誤的工具輸出都會產生相同的症狀:無聲的記憶丟失,且不會向使用者顯示任何錯誤。
本文提供的修復方案是架構上的調整,而非單純優化 Prompt:透過有序的模型鏈來執行整合,而不是只使用單一模型,這樣任何單一供應商的失敗都不會導致對話內容遺失。
如果您正在構建周邊產品介面而不僅僅是記憶子系統,請將此頁面與 單一金鑰聊天機器人指南 以及 AI API 速率限制指南 搭配閱讀。如果您是在比較供應商而非個別模型,請同時閱讀 OpenRouter 比較。
關鍵要點
- 記憶整合是一項狹窄的結構化輸出任務(工具呼叫或強制 JSON),而結構化輸出呼叫比自由對話有更多的失敗模式:架構違規、截斷、速率限制、逾時。
- 由單一模型處理整合是單點故障。請將整合視為一個可靠性問題並建立後備鏈 (fallback chain),而不是一個 Prompt 工程問題。
- 兩層鏈在實踐中效果良好:第一層是一系列低成本模型(DeepSeek V4 Flash、GLM-5.2、Qwen3.7 Plus、Gemini 3.5 Flash、GPT-5.5),它們在發生任何錯誤時會互相容錯。第二層僅在第一層所有模型都失敗時,才升級到 Claude Sonnet 5,然後是 Claude Opus 4.8。
- 本文沒有針對此特定執行環境發布可重現的失敗率或成本降低百分比。下方的定價計算僅供說明之用。在引用數據之前,請先測量您自己的工作負載。
- 由於該鏈是在獨立供應商之間進行容錯,而不是重複嘗試單一供應商,因此它不會將負載集中在單一速率限制上;且由於整合是作為非同步後台作業運行的,增加的重試延遲不會阻塞使用者面對的對話流程。
什麼是 AI Agent 記憶整合?
記憶整合是將原始對話記錄轉換為結構化、持久事實的過程:使用者偏好、決策、專案狀態、提及的實體等。這與 Agent 的主動上下文視窗(保存當前對話的訊息)不同。整合通常在每個對話結束時(關閉時、閒置逾時時或在滾動視窗中)運行一次,並將其輸出寫入資料庫、向量儲存或記憶服務,而不是寫回聊天中。
由於輸出必須符合架構(以便下游檢索代碼可以使用它),整合幾乎總是作為強制工具呼叫或 JSON 模式完成來實現,而不是普通的聊天回覆。這就是使其脆弱的細節:模型可以進行完美的對話,但仍可能因為返回了純文字而不是工具呼叫、在長對話記錄上截斷 JSON,或發明了您架構中不存在的欄位而導致整合步驟失敗。
為什麼單一模型整合會失敗
結構化輸出呼叫比普通聊天完成有更多的失敗模式:
- 模型忽略工具架構並返回純文字而不是工具呼叫。
- 供應商在流量高峰期間返回速率限制 (429) 或伺服器錯誤 (500/502/503)。
- 請求逾時,通常發生在需要更多 token 來總結的較長對話記錄上。
- 模型返回了有效的 JSON,但欄位名稱或類型與您的架構不符。
任何這些情況都會將一次完整的對話變成無聲的記憶缺口。使用者不會看到任何錯誤。他們會在稍後發現 Agent 「忘記」了某些事情,而到那時,如果您沒有單獨持久化原始對話記錄,它可能已經消失了。
我們尚未針對此特定執行環境、工作負載或日期發布受控的失敗率基準,因此我們不會在此重述具體百分比。可以驗證的是其機制:上述四種具體的命名失敗模式,一旦您將模型鏈接起來而不是呼叫單一模型,它們就不再是單點故障。
後備鏈的模型定價
下表列出了本文所述後備鏈中使用的模型的當前 TokenLab 定價。這是 TokenLab 的即時定價快照,與任何供應商發布的文件不同。在鎖定訂單之前請務必進行驗證,因為每 token 定價會隨時間變化。
| 模型 | 上下文視窗 | 輸入 $/MTok | 輸出 $/MTok | 來源 | 觀察日期 |
|---|---|---|---|---|---|
| DeepSeek V4 Flash | 1,048,576 | $0.09 | $0.18 | TokenLab 即時模型/定價快照 | 2026-07-09 |
| GLM-5.2 | 1,048,576 | $0.93 | $3.00 | TokenLab 即時模型/定價快照 | 2026-07-09 |
| Qwen3.7 Plus | 1,000,000 | $0.32 | $1.28 | TokenLab 即時模型/定價快照 | 2026-07-09 |
| Gemini 3.5 Flash | 1,048,576 | $1.50 | $9.00 | TokenLab 即時模型/定價快照 | 2026-07-09 |
| GPT-5.5 | 1,050,000 | $5.00 | $30.00 | TokenLab 即時模型/定價快照 | 2026-07-09 |
| Claude Sonnet 5 | 1,000,000 | $2.00 | $10.00 | TokenLab 即時模型/定價快照 | 2026-07-09 |
| Claude Opus 4.8 | 1,000,000 | $5.00 | $25.00 | TokenLab 即時模型/定價快照 | 2026-07-09 |
如需即時速率限制、最新定價和可靠性排名,請在確定鏈順序之前查看 TokenLab 模型目錄 和 模型排行榜。
如果您正在生產環境中路由記憶整合流量,請 開始使用 TokenLab,透過單一 API 金鑰存取這七個模型,而無需管理每個供應商單獨的憑證、速率限制和錯誤格式。
雙層後備架構
第一層:低成本、高容量、供應商多樣化
此層在每個整合事件上運行。按以下順序將模型跨至少三個不同供應商進行鏈接:
- DeepSeek V4 Flash
- GLM-5.2
- Qwen3.7 Plus
- Gemini 3.5 Flash
- GPT-5.5
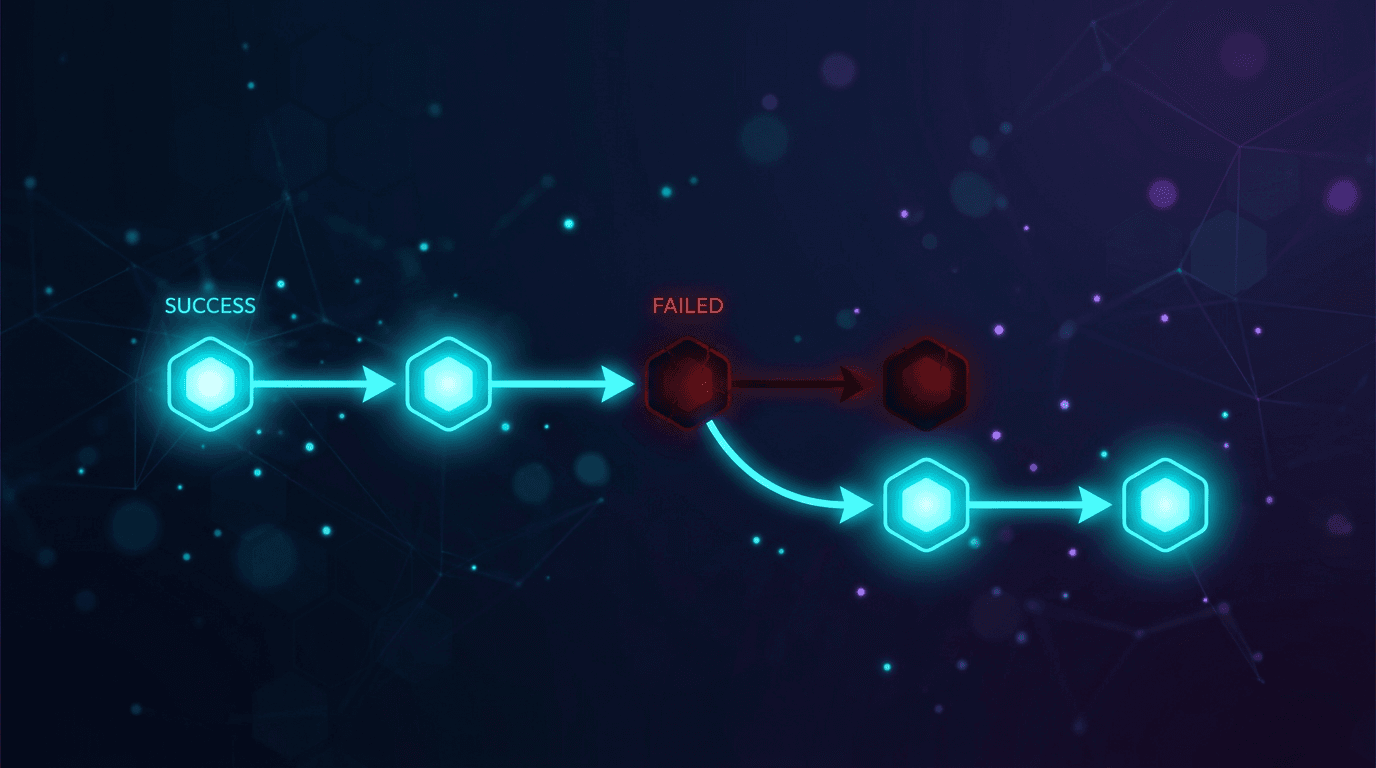
在任何工具呼叫失敗、架構違規、逾時或 4xx/5xx 回應時,立即移動到列表中的下一個模型。不要在第一層重複嘗試同一個模型;速率限制或格式錯誤的回應在立即重試時更有可能重複發生,而不是解決。
第二層:針對真實邊緣情況的升級
如果第一層所有模型都失敗,則升級到更強大的模型,而不是循環回到第一層:
- Claude Sonnet 5
- Claude Opus 4.8(最終後備)
第二層應該很少用到。如果您在日誌中頻繁看到第二層升級,這是一個信號,說明需要檢查您的第一層順序、架構嚴格性或對話記錄長度,而不是將第二層作為預設路徑的理由。
如何實作非同步後台記憶整合
整合絕不應阻塞使用者的下一條訊息。將其作為在對話結束或閒置逾時時觸發的後台作業運行,在完成時寫入您的記憶儲存,而不是在聊天回覆路徑中內聯執行。這種解耦也是使多模型鏈的最壞情況延遲可以接受的原因:後台工作人員中多幾秒鐘的重試對使用者面對的對話轉折沒有影響。
控制流程(不含代碼描述)如下:
- 在對話結束或閒置逾時時,將包含完整對話記錄的後台作業加入佇列。
- 工作人員嘗試針對第一層列表中的第一個模型進行整合,並設定每次嘗試的逾時限制。
- 發生逾時、429 或 5xx 時,工作人員立即移動到列表中的下一個模型,不對同一個模型進行原地重試。
- 收到 200 回應時,工作人員在接受之前根據您的 JSON 架構驗證負載。通過 HTTP 狀態檢查但未通過架構驗證的回應,處理方式與網路失敗相同:記錄並移動到下一個模型。
- 如果第一層所有模型都失敗,工作人員使用相同的逾時和驗證邏輯升級到第二層(Claude Sonnet 5,然後是 Claude Opus 4.8)。
- 如果兩層中的所有模型都失敗,工作人員將原始、未整合的對話記錄持久化到儲存中,並提醒值班工程師。無論整合結果如何,原始對話記錄絕不會被丟棄。
- 記錄哪個模型解決了每個事件(或整個鏈失敗),以便您可以測量自己的第一層解決率並在稍後重新排序鏈。
我們沒有發布包含這七個供應商特定 SDK 方法名稱、請求負載或回應形狀的可複製代碼範例,因為此證據集不包含每個供應商經過驗證的端點、驗證和負載詳細資訊,發明它們會產生看起來正確但在生產中無聲失敗的整合代碼。在實作此流程之前,請針對每個供應商自己的文件完成下方的驗證清單。
實作前的驗證清單
- 直接從每個供應商的官方 API 參考中確認當前端點、驗證標頭格式和請求主體形狀,而不是從第三方摘要中確認。
- 確認每個供應商的 SDK 對 429、500/502/503 和客戶端逾時引發的異常或錯誤物件,因為這些在不同 SDK 和 SDK 版本之間有所不同。
- 確認每個供應商的客戶端程式庫是否具有您需要禁用的內建重試機制,因為您在此鏈中需要的是跨供應商容錯,而不是針對同一個模型的程式庫內重試。
- 確認您的 JSON 架構驗證器在每次回應到達
persist_memory之前都會運行,包括返回 HTTP 200 的回應。 - 如果您透過 TokenLab 等多供應商閘道進行路由而不是直接呼叫每個供應商,請在假設供應商特定錯誤代碼保持不變之前,先在 tokenlab.sh/en/models 的文件中確認閘道自己的錯誤傳遞格式。
錯誤處理說明,對應真實失敗類別
| 錯誤類別 | 處理方式 |
|---|---|
| 429 速率限制 | 立即移動到下一個模型。不要在循環中重試同一個模型。如果一個模型重複觸發速率限制,請在未來呼叫中嘗試它之前增加短暫的冷卻時間。 |
| 500/502/503 伺服器錯誤 | 視為暫時性錯誤。移動到下一個模型。不要在此鏈中增加指數退避;容錯到不同的供應商比等待一個供應商的故障恢復更快。 |
| 逾時 | 限制每次嘗試(每次呼叫 5-10 秒的說明性限制;根據您的對話記錄長度進行調整)。逾時後,移動到下一個模型,而不是延長等待時間。 |
| 除 429 外的 4xx | 通常是您這邊的請求格式錯誤。大聲記錄並提醒人類;不要讓它在沒有可見性的情況下無聲地無限期容錯。 |
| 200 OK 但主體格式錯誤 | 在接受之前根據您的 JSON 架構進行驗證。語法有效但形狀錯誤的回應仍然是失敗,必須透過驗證捕獲,而不僅僅是透過 HTTP 狀態。 |
關於「這是否會導致速率限制耗盡」的異議:每個第一層模型都位於不同的供應商之後,因此一個供應商的 429 不會消耗另一個供應商的配額。該鏈分散了負載而不是集中負載。最壞的情況是,五次第一層嘗試加上兩次第二層嘗試共七次呼叫;以每次嘗試 8 秒的逾時限制計算,最壞情況限制在約一分鐘左右,且該場景需要每個供應商同時失敗,這是此設計旨在生存的罕見邊緣情況,而不是常見路徑。這是基於您配置的逾時的限制,而不是測量的生產延遲基準;我們沒有在負載下運行此鏈,也沒有報告測量的 p50/p99。
後備鏈的說明性成本比較
為了說明為什麼將大部分流量透過廉價模型路由很重要,以下是使用上述定價表的範例。假設:平均整合呼叫發送 3,000 個 token 的對話記錄作為輸入,並產生 400 個 token 的結構化輸出。這是一個說明性假設,而不是來自任何特定客戶工作負載的測量平均值;請替換您自己的 token 數量。
| 模型 | 每次呼叫成本(上述假設) |
|---|---|
| DeepSeek V4 Flash | $0.00034 |
| Qwen3.7 Plus | $0.00147 |
| GLM-5.2 | $0.00399 |
| Gemini 3.5 Flash | $0.00810 |
| Claude Sonnet 5 | $0.01000 |
| Claude Opus 4.8 | $0.02500 |
| GPT-5.5 | $0.02700 |
差異是真實存在的:在該假設下,將 100% 的呼叫透過 GPT-5.5 路由的成本大約是透過 DeepSeek V4 Flash 路由的 80 倍。我們在沒有您自己數據的情況下無法說明的是,您的流量中有多少比例實際在第一層解決,又有多少升級到第二層,因為這取決於您的對話記錄長度、架構複雜性和您運行當天的供應商可靠性。記錄哪個模型解決了每個事件(上述實作流程中的第 7 步),並在幾千個事件後計算您自己的混合成本,而不是依賴借來的百分比。
限制
- 此證據集中不存在針對此特定鏈、工作負載或日期的公開、可重現的失敗率基準。在引用具體數字之前,請在您自己的執行環境中進行日誌記錄。
- 上述成本表使用的是假設的 token 數量,而不是測量的平均對話記錄長度。請使用定價表的來源和觀察日期,用您自己的數字重新計算。
- 模型定價和上下文視窗會發生變化。在最終確定生產環境的鏈順序之前,請在 TokenLab 模型目錄 上確認當前值。
- 後備鏈降低了單點故障風險;它不能保證零數據丟失。請務必將原始對話記錄與結構化整合輸出分開持久化。
- 本文中的延遲和速率限制耗盡數據是基於可配置逾時的估計值,而非測量的生產基準。我們在此證據集中未在負載下運行此鏈。
- 本文特意不包含可複製貼上的請求代碼,因為在撰寫時無法驗證這七個供應商的確切端點、驗證標頭和負載證據。在實作之前,請使用驗證清單並參考每個供應商的官方文件。
實作清單
| 實踐 | 重要原因 |
|---|---|
| 驗證架構,而不僅僅是 HTTP 狀態 | 帶有格式錯誤 JSON 或缺失工具呼叫的 200 回應仍然是您的重試邏輯必須捕獲的失敗。 |
| 限制每次嘗試的逾時 | 限制最壞情況下的掛鐘時間,這樣一個緩慢的供應商就不會拖慢整個後台作業。 |
| 跨供應商容錯,而不是在一個供應商內 | 一個供應商的 429 或 503 應立即路由到不同的供應商,而不是重試同一個。 |
| 記錄哪個模型解決了每個事件 | 這是您測量自己第一層解決率並隨著定價和可靠性變化重新排序鏈的方式。 |
| 絕不丟棄原始對話記錄 | 即使在全鏈失敗時,也要持久化原始對話。失敗的結構化摘要可以恢復;刪除的對話記錄則無法恢復。 |
| 針對非 429/503 的 4xx 錯誤發出警報 | 這些通常表示您這邊的架構或請求錯誤,而不是暫時的供應商問題,不應被無聲地無限期重試。 |
| 部署前驗證每個供應商的 SDK 錯誤類型 | 429、5xx 和逾時的異常類別在不同供應商 SDK 之間有所不同,並且在 SDK 版本之間會發生變化;請檢查當前文件而不是進行假設。 |
對於超出個別模型之外的供應商級路由決策,OpenRouter 比較 涵蓋了多供應商路由如何改變速率限制和容錯行為。
常見問題解答
什麼是 AI Agent 記憶整合?
將原始對話記錄轉換為結構化、持久記憶(事實、偏好、決策)並寫入長期儲存的後台過程,通常在對話結束時透過強制工具呼叫或 JSON 模式完成。
如何實作非同步後台記憶整合而不阻塞聊天?
在對話結束或閒置逾時時將其作為後台工作人員作業觸發,與聊天回覆路徑分開。工作人員在完成時寫入您的記憶儲存;使用者的下一條訊息不會等待它。這也是使多模型重試延遲可以接受的原因,因為它發生在關鍵路徑之外。
5-7 個模型的重試鏈會導致延遲或速率限制問題嗎?
延遲風險受限於您的每次嘗試逾時,並透過非同步運行整合來吸收。速率限制風險得到緩解,因為該鏈在不同供應商之間進行容錯,而不是重複嘗試一個供應商,因此一個模型的 429 不會衝擊或耗盡另一個供應商的配額。這些是架構上的緩解措施,而非測量的延遲數字;我們尚未在生產負載下對此鏈進行基準測試。
哪個模型應該預設處理記憶整合?
從適合您容量的最便宜可靠模型開始,例如 DeepSeek V4 Flash,並在其後鏈接四到五個跨不同供應商的模型作為第一層。將 Claude Sonnet 5 和 Claude Opus 4.8 保留為僅作為第二層升級。在最終確定順序之前,請檢查 TokenLab 模型目錄 上的當前定價。
如果後備鏈中的每個模型都失敗了怎麼辦?
持久化未整合的原始對話記錄而不是丟棄它,提醒人類,並檢查對話記錄本身(長度、格式、編碼)是否在每個供應商處觸發了失敗,因為共同原因比七次獨立故障更有可能發生。
我怎麼知道這是否真的降低了我的成本?
記錄哪個層級解決了每個整合事件,並使用上面的每模型定價表從您自己的數據中計算混合成本。不要依賴借來的百分比;您的解決率取決於您的對話記錄長度、架構嚴格性和供應商可靠性。
為什麼這篇文章不包含可運行的 API 代碼?
因為此證據集不包含鏈中所有七個供應商經過驗證的當前端點、驗證和負載詳細資訊,發布看起來合理但未經驗證的請求代碼將比沒有代碼更糟。在編寫整合之前,請針對每個供應商的官方 API 參考使用上面的驗證清單。
開始使用
如果您正在構建無法承受無聲丟失上下文的 Agent 記憶,請 開始使用 TokenLab,透過單一 API 金鑰比較當前定價並跨此後備鏈中的模型路由整合流量,而不是管理每個供應商單獨的憑證和速率限制。
來源
價格觀測於 2026-07-07
- fal PixVerse V6 model page觀測於 2026-07-09
- fal FLUX.2 model page觀測於 2026-07-09
- TokenLab model directory觀測於 2026-07-07