Forschung
Wie TokenLab die Zuverlässigkeit von AI APIs stärkt: Verträge, Observability und Model Truth
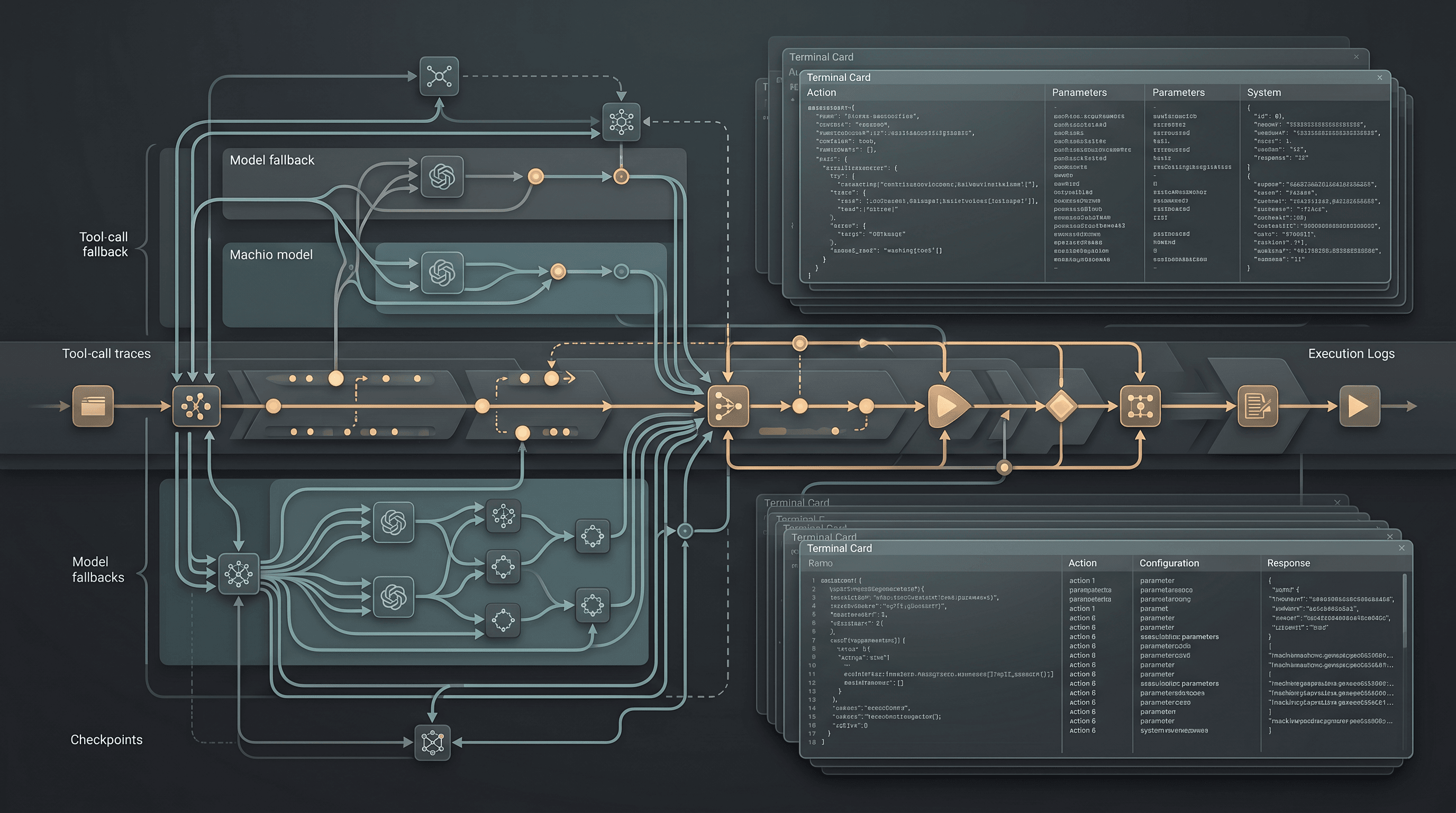
Die Zuverlässigkeit von AI APIs hängt von expliziten Request-Verträgen, nützlicher Fehlersemantik, Observability auf Request-Ebene und der aktuellen Modellwahrheit ab. TokenLab betrachtet diese als ein einziges System.
9. JuliCrypto