Bir kullanıcı, ajanınızla 30 dakikalık bir oturumu bitirir. Gereksinimlerini paylaşmış, tercihlerini belirtmiş, kararlar almıştır. Ardından yeni bir oturum başlatır ve bunların hiçbiri aktarılmaz. Genellikle bozulan şey ajanın muhakeme yeteneği değil, AI ajan bellek konsolidasyonudur: ham bir dökümü yapılandırılmış uzun süreli belleğe dönüştüren arka plan adımı. Bu adım, tek bir modele yapılan tek bir API çağrısıdır ve tek API çağrıları başarısız olur. Hız sınırları (rate limits), zaman aşımları ve hatalı biçimlendirilmiş araç çıktıları, aynı belirtiyi üretir: kullanıcıya hiçbir hata gösterilmeden sessiz bellek kaybı.
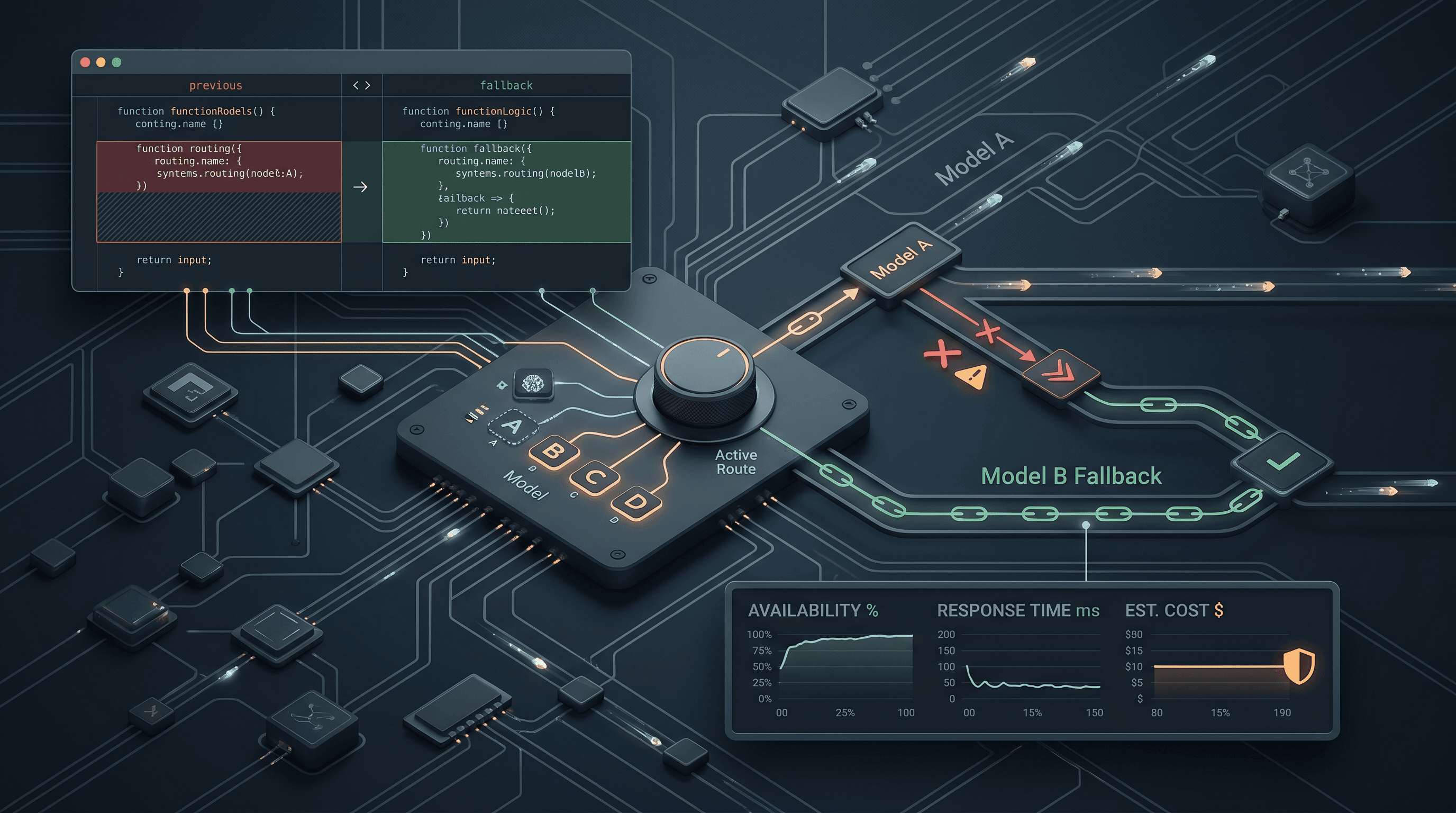
Bu makaledeki çözüm, daha iyi bir istem (prompt) değil, mimari bir çözümdür: konsolidasyonu tek bir model yerine sıralı bir model zinciri üzerinden çalıştırın, böylece herhangi bir sağlayıcıdaki hata konuşmayı silmez.
Sadece bellek alt sistemini değil, çevresindeki ürün yüzeyini de inşa ediyorsanız, bu sayfayı tek anahtarlı sohbet botu kılavuzu ve AI API hız sınırlama kılavuzu ile eşleştirin. Bireysel modeller yerine sağlayıcıları karşılaştırıyorsanız, OpenRouter karşılaştırmasını bununla birlikte okuyun.
Temel Çıkarımlar
- Bellek konsolidasyonu, dar ve yapılandırılmış bir çıktı görevidir (araç çağrısı veya zorunlu JSON) ve yapılandırılmış çıktı çağrıları, serbest biçimli sohbetten daha fazla hata moduna sahiptir: şema ihlalleri, kırpılma, hız sınırları, zaman aşımları.
- Konsolidasyonu yöneten tek bir model, tek bir hata noktasıdır. Konsolidasyonu bir istem mühendisliği sorunu olarak değil, yedekleme zincirine sahip bir güvenilirlik sorunu olarak ele alın.
- İki katmanlı bir zincir pratikte iyi çalışır: 1. Katman, herhangi bir hatada birbirine devreden düşük maliyetli modeller dizisidir (DeepSeek V4 Flash, GLM-5.2, Qwen3.7 Plus, Gemini 3.5 Flash, GPT-5.5). 2. Katman, yalnızca tüm 1. Katman modelleri başarısız olduğunda Claude Sonnet 5'e, ardından Claude Opus 4.8'e yükseltilir.
- Bu makale, bu çalışma zamanı için yayınlanmış, tekrarlanabilir bir hata oranı veya maliyet düşürme yüzdesine sahip değildir. Aşağıdaki fiyatlandırma matematiği açıklayıcıdır ve bu şekilde etiketlenmiştir. Bir sayı belirtmeden önce kendi iş yükünüzü ölçün.
- Zincir, bir sağlayıcıyı tekrar tekrar denemek yerine bağımsız sağlayıcılar arasında devretme yaptığı için, yükü tek bir hız sınırında yoğunlaştırmaz ve konsolidasyon asenkron bir arka plan işi olarak çalıştığı için, eklenen yeniden deneme gecikmesi kullanıcıya dönük sohbet sırasını engellemez.
AI ajan bellek konsolidasyonu nedir?
Bellek konsolidasyonu, ham bir konuşma dökümünü yapılandırılmış, kalıcı gerçeklere (kullanıcı tercihleri, kararlar, proje durumu, bahsedilen varlıklar) dönüştürme sürecidir. Bu, mevcut oturumun mesajlarını tutan ajanın aktif bağlam penceresinden farklıdır. Konsolidasyon genellikle oturum başına bir kez (kapatıldığında, boşta kalma zaman aşımında veya kayan bir pencerede) çalışır ve çıktısını sohbetin içine değil, bir veritabanına, vektör deposuna veya bellek hizmetine yazar.
Çıktı bir şemayla eşleşmek zorunda olduğundan (böylece sonraki alma kodu onu kullanabilir), konsolidasyon neredeyse her zaman düz bir sohbet yanıtı olarak değil, zorunlu bir araç çağrısı veya JSON modu tamamlaması olarak uygulanır. Onu kırılgan yapan detay budur: bir model mükemmel bir konuşma yürütebilir ancak araç çağrısı yerine düzyazı döndürerek, uzun bir dökümde JSON'u kırparak veya şemanızda olmayan bir alan icat ederek konsolidasyon adımında başarısız olabilir.
Tek model konsolidasyonu neden başarısız olur?
Yapılandırılmış çıktı çağrıları, normal bir sohbet tamamlamasından daha fazla hata moduna sahiptir:
- Model, araç şemasını görmezden gelir ve araç çağrısı yerine düzyazı döndürür.
- Sağlayıcı, trafik artışı sırasında bir hız sınırı (429) veya sunucu hatası (500/502/503) döndürür.
- İstek, genellikle özetlemek için daha fazla token gerektiren daha uzun dökümlerde zaman aşımına uğrar.
- Model, şemanızla eşleşmeyen bir alan adı veya türü içeren geçerli JSON döndürür.
Bunların herhangi biri, tamamlanmış bir konuşmayı sessiz bir bellek boşluğuna dönüştürür. Kullanıcıya gösterilen bir hata yoktur. Daha sonra ajan bir şeyi "unuttuğunda" fark ederler ve o zamana kadar, eğer ayrı olarak saklamadıysanız ham döküm zaten gitmiş olabilir.
Bu çalışma zamanı, iş yükü veya tarih için kontrollü bir hata oranı kıyaslaması yayınlamadık, bu yüzden burada belirli bir yüzdeyi yeniden belirtmeyeceğiz. Doğrulanabilir olan şey mekanizmadır: yukarıdaki dört somut, adlandırılmış hata modu; tek bir modeli çağırmak yerine modelleri zincirlediğinizde, hepsi tek hata noktası olmaktan çıkar.
Yedekleme zinciri için model fiyatlandırması
Aşağıdaki tablo, bu makalede açıklanan yedekleme zincirinde kullanılan modeller için güncel TokenLab fiyatlandırmasını listeler. Bu, herhangi bir sağlayıcı tarafından yayınlanan belgelerden farklı, TokenLab canlı fiyatlandırma anlık görüntüsüdür. Token başına fiyatlandırma zamanla değiştiğinden, bir siparişi kilitlemeden önce bunları doğrulayın.
| Model | Bağlam penceresi | Girdi $/MTok | Çıktı $/MTok | Kaynak | Gözlemlenen |
|---|---|---|---|---|---|
| DeepSeek V4 Flash | 1,048,576 | $0.09 | $0.18 | TokenLab canlı model/fiyatlandırma anlık görüntüsü | 2026-07-09 |
| GLM-5.2 | 1,048,576 | $0.93 | $3.00 | TokenLab canlı model/fiyatlandırma anlık görüntüsü | 2026-07-09 |
| Qwen3.7 Plus | 1,000,000 | $0.32 | $1.28 | TokenLab canlı model/fiyatlandırma anlık görüntüsü | 2026-07-09 |
| Gemini 3.5 Flash | 1,048,576 | $1.50 | $9.00 | TokenLab canlı model/fiyatlandırma anlık görüntüsü | 2026-07-09 |
| GPT-5.5 | 1,050,000 | $5.00 | $30.00 | TokenLab canlı model/fiyatlandırma anlık görüntüsü | 2026-07-09 |
| Claude Sonnet 5 | 1,000,000 | $2.00 | $10.00 | TokenLab canlı model/fiyatlandırma anlık görüntüsü | 2026-07-09 |
| Claude Opus 4.8 | 1,000,000 | $5.00 | $25.00 | TokenLab canlı model/fiyatlandırma anlık görüntüsü | 2026-07-09 |
Canlı hız sınırları, en son fiyatlandırma ve güvenilirlik sıralamaları için, zincir sıranızı kesinleştirmeden önce TokenLab model dizinini ve model liderlik tablosunu kontrol edin.
Üretimde bellek konsolidasyonu trafiğini yönlendiriyorsanız, sağlayıcı başına ayrı kimlik bilgileri, hız sınırları ve hata biçimlerini yönetmek yerine tek bir API anahtarı üzerinden bu yedi modele ulaşmak için TokenLab ile başlayın.
Çift katmanlı yedekleme mimarisi
1. Katman: ucuz, yüksek hacimli, sağlayıcı çeşitliliği
Bu katman her konsolidasyon olayında çalışır. Modelleri en az üç farklı sağlayıcı arasında, şu sırayla zincirleyin:
- DeepSeek V4 Flash
- GLM-5.2
- Qwen3.7 Plus
- Gemini 3.5 Flash
- GPT-5.5
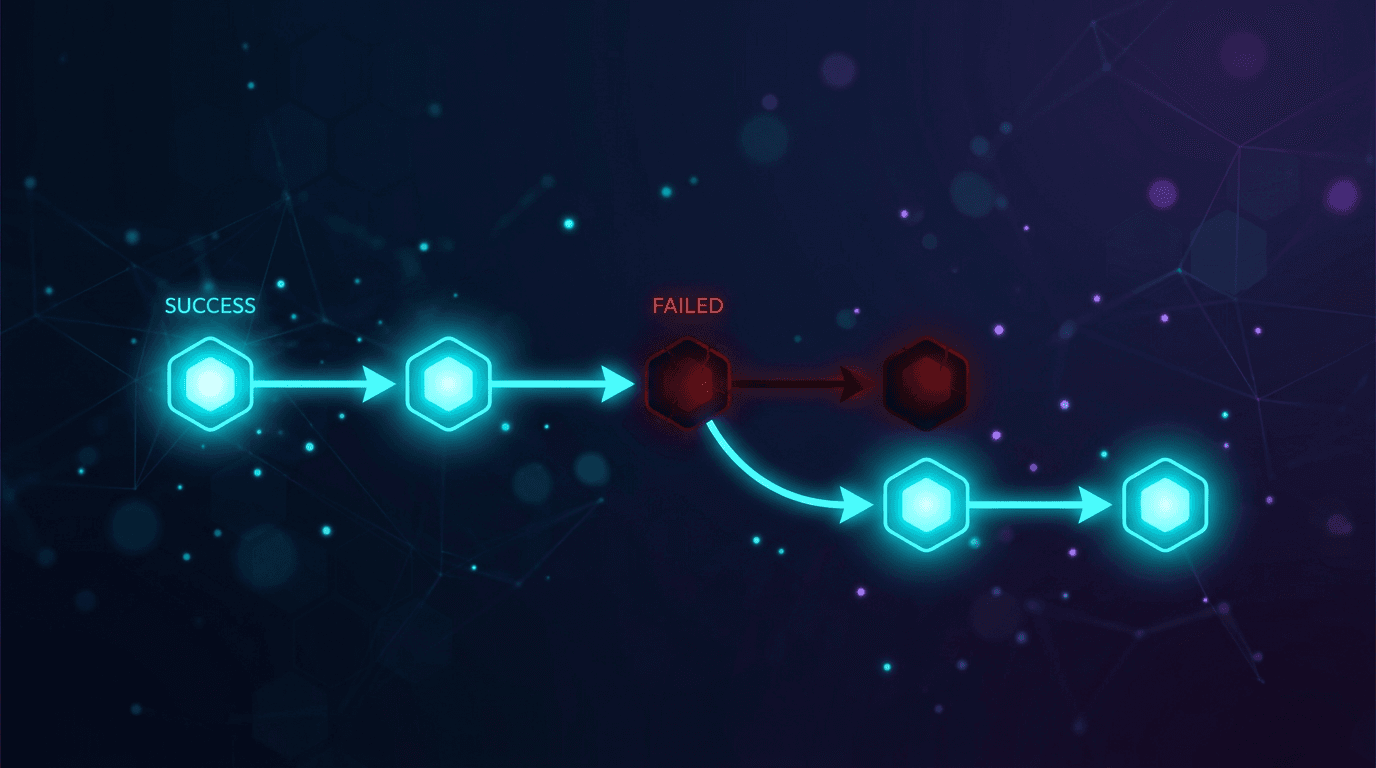
Herhangi bir araç çağrısı hatasında, şema ihlalinde, zaman aşımında veya 4xx/5xx yanıtında, hemen listedeki bir sonraki modele geçin. 1. Katmandaki aynı modeli yeniden denemeyin; bir hız sınırı veya hatalı biçimlendirilmiş yanıtın anında yeniden denemede çözülmesinden ziyade tekrarlanması daha olasıdır.
2. Katman: gerçek uç durumlar için yükseltme
Her 1. Katman modeli başarısız olursa, 1. Katman üzerinden geri dönmek yerine daha güçlü bir modele yükseltin:
- Claude Sonnet 5
- Claude Opus 4.8 (nihai yedekleme)
2. Katman nadir olmalıdır. Günlüklerinizde sık sık 2. Katman yükseltmeleri görüyorsanız, bu 1. Katman sıranızı, şema katılığınızı veya döküm uzunluğunuzu kontrol etmeniz için bir işarettir, 2. Katmanı varsayılan yolunuz yapmanız için bir neden değildir.
Asenkron arka plan bellek konsolidasyonu nasıl uygulanır?
Konsolidasyon, kullanıcının bir sonraki mesajını asla engellememelidir. Sohbet yanıtı yolunda satır içi değil, oturum kapandığında veya boşta kalma zaman aşımında tetiklenen bir arka plan işi olarak çalıştırın ve tamamlandığında bellek deponuza yazın. Bu ayrıştırma, çok modelli bir zincirin en kötü durum gecikmesini kabul edilebilir kılan şeydir: bir arka plan çalışanındaki birkaç saniyelik ekstra yeniden deneme, kullanıcıya dönük tur üzerinde hiçbir etkiye sahip değildir.
Kod olmadan açıklanan kontrol akışı şöyledir:
- Oturum kapandığında veya boşta kalma zaman aşımında, tam dökümü içeren bir arka plan işini sıraya alın.
- Çalışan, deneme başına sınırlı bir zaman aşımı ile 1. Katman listesindeki ilk modele karşı konsolidasyon dener.
- Zaman aşımı, 429 veya 5xx durumunda, çalışan aynı modele karşı yerinde yeniden deneme yapmadan hemen listedeki bir sonraki modele geçer.
- 200 yanıtında, çalışan yükü kabul etmeden önce JSON şemanıza göre doğrular. HTTP durum kontrolünü geçen ancak şema doğrulamasında başarısız olan bir yanıt, ağ hatasıyla aynı şekilde ele alınır: günlüğe kaydedin ve bir sonraki modele geçin.
- Her 1. Katman modeli başarısız olursa, çalışan aynı zaman aşımı ve doğrulama mantığını kullanarak 2. Katmana (Claude Sonnet 5, ardından Claude Opus 4.8) yükseltilir.
- Her iki katmandaki her model başarısız olursa, çalışan ham, konsolide edilmemiş dökümü depolama alanına kaydeder ve bir nöbetçi mühendisi uyarır. Ham döküm, konsolidasyonun nasıl sonuçlandığına bakılmaksızın asla atılmaz.
- Hangi modelin her olayı çözdüğünü (veya tüm zincirin başarısız olduğunu) günlüğe kaydedin, böylece kendi 1. Katman çözüm oranınızı ölçebilir ve zinciri daha sonra yeniden sıralayabilirsiniz.
Bu yedi sağlayıcı için belirli SDK yöntem adlarını, istek yüklerini veya yanıt şekillerini içeren kopyala-yapıştır yapılabilir bir kod örneği yayınlamıyoruz, çünkü bu kanıt seti her biri için doğrulanmış uç nokta, kimlik doğrulama ve yük detaylarını içermemektedir ve bunları icat etmek, doğru görünen ancak üretimde sessizce başarısız olan entegrasyon kodu üretirdi. Bu akışı uygulamadan önce, aşağıdaki doğrulama kontrol listesini her sağlayıcının kendi belgelerine karşı çalıştırın.
Uygulamadan önce doğrulama kontrol listesi
- Her sağlayıcının yapılandırılmış çıktı veya araç çağırma modu için güncel uç noktayı, kimlik doğrulama başlığı biçimini ve istek gövdesi şeklini, üçüncü taraf bir özetten değil, doğrudan resmi API referansından onaylayın.
- Her sağlayıcının SDK'sının 429, 500/502/503 ve istemci tarafı zaman aşımları için hangi istisna veya hata nesnesini yükselttiğini onaylayın, çünkü bunlar SDK'ya göre farklılık gösterir ve SDK sürümleri arasında değişir.
- Her sağlayıcının istemci kitaplığının, devre dışı bırakmanız gereken yerleşik bir yeniden deneme mekanizmasına sahip olup olmadığını onaylayın, çünkü bu zincirde kitaplık içi yeniden deneme değil, sağlayıcılar arası devretme istiyorsunuz.
- JSON şema doğrulayıcınızın, HTTP 200 döndüren yanıtlar dahil olmak üzere,
persist_memory'ye ulaşmadan önce her yanıtta çalıştığını onaylayın. - Her sağlayıcıyı doğrudan çağırmak yerine TokenLab gibi çok sağlayıcılı bir ağ geçidi üzerinden yönlendiriyorsanız, sağlayıcıya özgü hata kodlarının değişmeden yayıldığını varsaymadan önce ağ geçidinin kendi hata geçiş biçimini tokenlab.sh/en/models adresindeki belgelerinden onaylayın.
Gerçek hata sınıflarıyla eşleştirilmiş hata işleme notları
| Hata sınıfı | İşleme |
|---|---|
| 429 hız sınırı aşıldı | Hemen bir sonraki modele geçin. Aynı modeli döngü içinde yeniden denemeyin. Bir model sürekli hız sınırı koyuyorsa, gelecekteki çağrılarda tekrar denenmeden önce kısa bir soğuma süresi ekleyin. |
| 500/502/503 sunucu hatası | Geçici olarak ele alın. Bir sonraki modele geçin. Bu zincirin içine üstel geri çekilme (exponential backoff) eklemeyin; farklı bir sağlayıcıya devretme, bir sağlayıcının kesintisini beklemekten daha hızlıdır. |
| Zaman aşımı | Her denemeyi sınırlayın (çağrı başına 5-10 saniyelik açıklayıcı bir sınır; döküm uzunluğunuza göre ayarlayın). Zaman aşımında, beklemeyi uzatmak yerine bir sonraki modele geçin. |
| 429 dışındaki 4xx | Genellikle sizin tarafınızda bir istek biçimi hatasıdır. Yüksek sesle günlüğe kaydedin ve bir insanı uyarın; görünürlük olmadan sonsuza kadar sessizce devretmesine izin vermeyin. |
| Hatalı gövdeli 200 OK | Kabul etmeden önce JSON şemanıza göre doğrulayın. Sözdizimsel olarak geçerli ancak yanlış şekle sahip bir yanıt hala bir hatadır ve yalnızca HTTP durumuyla değil, doğrulama ile yakalanmalıdır. |
"Bu, hız sınırı tükenmesine neden olur mu?" itirazına gelince: her 1. Katman modeli farklı bir sağlayıcının arkasında durur, bu nedenle birindeki 429, başka bir sağlayıcının kotasını tüketmez. Zincir, yükü yoğunlaştırmak yerine dağıtır. En kötü durumda, beş 1. Katman denemesi artı iki 2. Katman denemesi yedi çağrıdır; deneme başına 8 saniyelik zaman aşımı sınırı ile bu, en kötü durumu bir dakika civarında sınırlar ve bu senaryo her sağlayıcının aynı anda başarısız olmasını gerektirir ki bu, bu tasarımın hayatta kalmak için oluşturulduğu nadir uç durumdur, ortak yol değildir. Bu, yapılandırdığınız zaman aşımlarına dayalı bir sınırdır, ölçülen bir üretim gecikmesi kıyaslaması değildir; bu zinciri yük altında çalıştırmadık ve ölçülen bir p50/p99 rapor etmiyoruz.
Yedekleme zinciri genelinde açıklayıcı maliyet karşılaştırması
Çoğu hacmi ucuz modeller üzerinden yönlendirmenin neden önemli olduğunu göstermek için, yukarıdaki fiyatlandırma tablosunu kullanan bir örnek çalışma aşağıdadır. Varsayım: ortalama bir konsolidasyon çağrısı, girdi olarak 3.000 tokenlik bir döküm gönderir ve 400 tokenlik yapılandırılmış çıktı üretir. Bu, herhangi bir müşteri iş yükünden ölçülen bir ortalama değil, açıklayıcı bir varsayımdır; kendi token sayılarınızı yerine koyun.
| Model | Çağrı başına maliyet (yukarıdaki varsayım) |
|---|---|
| DeepSeek V4 Flash | $0.00034 |
| Qwen3.7 Plus | $0.00147 |
| GLM-5.2 | $0.00399 |
| Gemini 3.5 Flash | $0.00810 |
| Claude Sonnet 5 | $0.01000 |
| Claude Opus 4.8 | $0.02500 |
| GPT-5.5 | $0.02700 |
Fark gerçektir: bu varsayım altında, çağrıların %100'ünü GPT-5.5 üzerinden yönlendirmek, DeepSeek V4 Flash üzerinden yönlendirmekten yaklaşık 80 kat daha maliyetlidir. Kendi verileriniz olmadan belirtemeyeceğimiz şey, trafiğinizin ne kadarının 1. Katmanda çözüldüğü ve ne kadarının 2. Katmana yükseltildiğidir, çünkü bu döküm uzunluğunuza, şema karmaşıklığınıza ve çalıştırdığınız günkü sağlayıcı güvenilirliğine bağlıdır. Hangi modelin her olayı çözdüğünü günlüğe kaydedin (yukarıdaki uygulama akışında 7. adım) ve ödünç alınmış bir yüzdeye güvenmek yerine birkaç bin olaydan sonra kendi harmanlanmış maliyetinizi hesaplayın.
Sınırlamalar
- Bu kanıt setinde bu tam zincir, iş yükü veya tarih için halka açık, tekrarlanabilir bir hata oranı kıyaslaması yoktur. Belirli bir sayı belirtmeden önce kendi çalışma zamanınızda günlük kaydını araçlandırın.
- Yukarıdaki maliyet tablosu, ölçülen ortalama döküm uzunluğunu değil, varsayılan bir token sayısını kullanır. Fiyatlandırma tablosunun kaynağını ve gözlemlenen tarihini kullanarak kendi sayılarınızla yeniden hesaplayın.
- Model fiyatlandırması ve bağlam pencereleri değişir. Üretim için bir zincir sırasını kesinleştirmeden önce TokenLab model dizinindeki güncel değerleri onaylayın.
- Bir yedekleme zinciri, tek hata noktası riskini azaltır; sıfır veri kaybını garanti etmez. Ham dökümü her zaman yapılandırılmış konsolidasyon çıktısından ayrı olarak saklayın.
- Bu makaledeki gecikme ve hız sınırı tükenme rakamları, ölçülen üretim kıyaslamaları değil, yapılandırılabilir zaman aşımlarına dayalı tahminlerdir. Bu zinciri bu kanıt setinde yük altında çalıştırmadık.
- Bu makale kasıtlı olarak kopyala-yapıştır yapılabilir istek kodu içermemektedir, çünkü bu yedi sağlayıcı için kesin uç nokta, kimlik doğrulama başlığı ve yük kanıtları yazım sırasında doğrulanabilir değildi. Uygulamadan önce doğrulama kontrol listesini ve her sağlayıcının resmi belgelerini kullanın.
Uygulama kontrol listesi
| Uygulama | Neden önemli |
|---|---|
| HTTP durumunu değil, şemayı doğrulayın | Hatalı biçimlendirilmiş JSON veya eksik araç çağrısı içeren bir 200 yanıtı, yeniden deneme mantığınızın yakalaması gereken bir hatadır. |
| Deneme başına zaman aşımını sınırlayın | En kötü durumdaki duvar saati süresini sınırlayın, böylece yavaş bir sağlayıcı tüm arka plan işini durdurmaz. |
| Bir sağlayıcı içinde değil, sağlayıcılar arasında devredin | Bir sağlayıcıdaki 429 veya 503, aynı sağlayıcıyı yeniden denemek yerine derhal farklı bir sağlayıcıya yönlendirilmelidir. |
| Hangi modelin her olayı çözdüğünü günlüğe kaydedin | Kendi 1. Katman çözüm oranınızı bu şekilde ölçer ve fiyatlandırma ile güvenilirlik değiştikçe zinciri yeniden sıralarsınız. |
| Ham dökümü asla bırakmayın | Tam zincir başarısızlığında bile ham konuşmayı saklayın. Başarısız bir yapılandırılmış özet kurtarılabilir; silinmiş bir döküm kurtarılamaz. |
| 429/503 dışındaki 4xx hatalarında uyarın | Bunlar genellikle geçici bir sağlayıcı sorunu değil, sizin tarafınızdaki bir şema veya istek hatasını gösterir ve sonsuza kadar sessizce yeniden denenmemelidir. |
| Dağıtmadan önce sağlayıcı başına SDK hata türlerini doğrulayın | 429, 5xx ve zaman aşımları için istisna sınıfları sağlayıcı SDK'ları arasında farklılık gösterir ve SDK sürümleri arasında değişir; varsaymak yerine güncel belgeleri kontrol edin. |
Bireysel modellerin ötesindeki sağlayıcı düzeyinde yönlendirme kararları için, OpenRouter karşılaştırması, çok sağlayıcılı yönlendirmenin hız sınırı ve devretme davranışını nasıl değiştirdiğini kapsar.
SSS
AI ajan bellek konsolidasyonu nedir?
Ham bir konuşma dökümünü, genellikle oturum sonunda zorunlu bir araç çağrısı veya JSON modu tamamlaması yoluyla uzun süreli depolamaya yazılan yapılandırılmış, kalıcı belleğe (gerçekler, tercihler, kararlar) dönüştüren arka plan sürecidir.
Sohbeti engellemeden asenkron arka plan bellek konsolidasyonunu nasıl uygularım?
Sohbet yanıtı yolundan ayrı olarak, oturum kapandığında veya boşta kalma zaman aşımında bir arka plan çalışanı işi olarak tetikleyin. Çalışan, bittiğinde bellek deponuza yazar; kullanıcının bir sonraki mesajı onu beklemez. Çok modelli yeniden deneme gecikmesini kabul edilebilir kılan şey de budur, çünkü kritik yolun dışında gerçekleşir.
5-7 modelli bir yeniden deneme zinciri gecikme veya hız sınırı sorunlarına neden olur mu?
Gecikme riski, deneme başına zaman aşımınızla sınırlıdır ve konsolidasyonu asenkron olarak çalıştırarak emilir. Hız sınırı riski, zincir bir sağlayıcıyı tekrar tekrar denemek yerine farklı sağlayıcılar arasında devretme yaptığı için azaltılır, bu nedenle bir modeldeki 429, başka bir sağlayıcının kotasını zorlamaz veya tüketmez. Bunlar mimari hafifletmelerdir, ölçülen gecikme sayıları değildir; bu zinciri üretim yükü altında kıyaslamadık.
Bellek konsolidasyonunu varsayılan olarak hangi model yönetmelidir?
Hacminiz için DeepSeek V4 Flash gibi en ucuz güvenilir modelle başlayın ve arkasına 1. Katman olarak farklı sağlayıcılardan dört veya beş model zincirleyin. Claude Sonnet 5 ve Claude Opus 4.8'i yalnızca 2. Katman yükseltmesi olarak ayırın. Sırayı kesinleştirmeden önce TokenLab model dizinindeki güncel fiyatlandırmayı kontrol edin.
Yedekleme zincirindeki her model başarısız olursa ne olur?
Ham dökümü atmak yerine konsolide edilmemiş şekilde saklayın, bir insanı uyarın ve dökümün kendisinin (uzunluk, biçim, kodlama) her sağlayıcıda hatayı tetikleyip tetiklemediğini kontrol edin, çünkü ortak bir neden yedi bağımsız kesintiden daha olasıdır.
Bunun maliyetimi gerçekten düşürdüğünü nasıl anlarım?
Hangi katmanın her konsolidasyon olayını çözdüğünü günlüğe kaydedin ve yukarıdaki model başına fiyatlandırma tablosunu kullanarak kendi verilerinizden harmanlanmış maliyeti hesaplayın. Ödünç alınmış bir yüzdeye güvenmeyin; çözüm oranınız döküm uzunluğunuza, şema katılığınıza ve sağlayıcı güvenilirliğine bağlıdır.
Bu makale neden çalışan API kodu içermiyor?
Çünkü bu kanıt seti, zincirdeki yedi sağlayıcının tümü için doğrulanmış güncel uç nokta, kimlik doğrulama ve yük detaylarını içermemektedir ve makul görünen ancak doğrulanmamış istek kodu yayınlamak, hiç kod olmamasından daha kötü olurdu. Entegrasyonunuzu yazmadan önce yukarıdaki doğrulama kontrol listesini her sağlayıcının resmi API referansına karşı kullanın.
Başlayın
Sessizce bağlam kaybetmeyi göze alamayan bir ajan belleği oluşturuyorsanız, sağlayıcı başına ayrı kimlik bilgileri ve hız sınırlarını yönetmek yerine, güncel fiyatlandırmayı karşılaştırmak ve konsolidasyon trafiğini bu yedekleme zincirindeki modeller arasında tek bir API anahtarı üzerinden yönlendirmek için TokenLab ile başlayın.
Kaynaklar
Fiyat 2026-07-07 tarihinde gözlendi
- fal PixVerse V6 model page2026-07-09 tarihinde gözlendi
- fal FLUX.2 model page2026-07-09 tarihinde gözlendi
- TokenLab model directory2026-07-07 tarihinde gözlendi