Ein Benutzer beendet eine 30-minütige Sitzung mit Ihrem Agenten. Er hat Anforderungen mitgeteilt, Präferenzen geäußert und Entscheidungen getroffen. Dann startet er eine neue Sitzung, und nichts davon ist mehr vorhanden. Was normalerweise kaputtgegangen ist, ist nicht das Schlussfolgerungsvermögen des Agenten, sondern die Konsolidierung des AI-Agent-Gedächtnisses: der Hintergrundschritt, der ein rohes Transkript in strukturiertes Langzeitgedächtnis umwandelt. Dieser Schritt ist ein einzelner API-Aufruf an ein einzelnes Modell, und einzelne API-Aufrufe schlagen fehl. Ratenbegrenzungen (Rate Limits), Timeouts und fehlerhafte Tool-Ausgaben führen alle zum gleichen Symptom: stiller Gedächtnisverlust, ohne dass dem Benutzer ein Fehler angezeigt wird.
Die Lösung in diesem Artikel ist architektonischer Natur, nicht ein besseres Prompt: Führen Sie die Konsolidierung über eine geordnete Kette von Modellen durch, anstatt über ein einziges, damit ein Ausfall bei einem einzelnen Anbieter nicht das gesamte Gespräch löscht.
Wenn Sie die umgebende Produktoberfläche und nicht nur das Gedächtnis-Subsystem entwickeln, kombinieren Sie diese Seite mit dem One-Key-Chatbot-Leitfaden und dem Leitfaden zur AI-API-Ratenbegrenzung. Wenn Sie Anbieter anstelle einzelner Modelle vergleichen, lesen Sie den OpenRouter-Vergleich zusätzlich zu diesem.
Wichtige Erkenntnisse
- Die Gedächtniskonsolidierung ist eine eng gefasste Aufgabe mit strukturierter Ausgabe (Tool-Aufruf oder erzwungenes JSON), und Aufrufe mit strukturierter Ausgabe haben mehr Fehlerquellen als freie Chats: Schemaverletzungen, Kürzungen, Ratenbegrenzungen, Timeouts.
- Ein einzelnes Modell, das die Konsolidierung übernimmt, ist ein Single Point of Failure. Betrachten Sie die Konsolidierung als Zuverlässigkeitsproblem mit einer Fallback-Kette, nicht als Problem des Prompt-Engineerings.
- Eine zweischichtige Kette funktioniert in der Praxis gut: Schicht 1 ist eine Sequenz kostengünstiger Modelle (DeepSeek V4 Flash, GLM-5.2, Qwen3.7 Plus, Gemini 3.5 Flash, GPT-5.5), die bei jedem Fehler aufeinander zurückgreifen. Schicht 2 eskaliert auf Claude Sonnet 5 und dann auf Claude Opus 4.8, nur wenn jedes Modell der Schicht 1 fehlschlägt.
- Dieser Artikel enthält keine veröffentlichte, reproduzierbare Ausfallrate oder Kostenreduzierungsrate für diese spezifische Laufzeit. Die unten stehenden Preisberechnungen sind illustrativ und als solche gekennzeichnet. Messen Sie Ihre eigene Arbeitslast, bevor Sie eine Zahl nennen.
- Da die Kette über unabhängige Anbieter hinweg ausweicht, anstatt einen Anbieter wiederholt abzufragen, konzentriert sie die Last nicht auf ein einzelnes Rate Limit. Da die Konsolidierung als asynchroner Hintergrundjob läuft, blockiert die zusätzliche Retry-Latenz nicht den benutzerseitigen Chat-Turn.
Was ist die Konsolidierung des AI-Agent-Gedächtnisses?
Die Gedächtniskonsolidierung ist der Prozess der Umwandlung eines rohen Gesprächstranskripts in strukturierte, dauerhafte Fakten: Benutzerpräferenzen, Entscheidungen, Projektstatus, erwähnte Entitäten. Dies unterscheidet sich vom aktiven Kontextfenster des Agenten, das die Nachrichten der aktuellen Sitzung enthält. Die Konsolidierung läuft normalerweise einmal pro Sitzung (beim Schließen, bei einem Leerlauf-Timeout oder in einem rollierenden Fenster) und schreibt ihre Ausgabe in eine Datenbank, einen Vektorspeicher oder einen Gedächtnisdienst, anstatt sie zurück in den Chat zu schreiben.
Da die Ausgabe einem Schema entsprechen muss (damit nachgelagerter Abrufcode sie verwenden kann), wird die Konsolidierung fast immer als erzwungener Tool-Aufruf oder als JSON-Modus-Vervollständigung implementiert, nicht als einfache Chat-Antwort. Das ist das Detail, das sie anfällig macht: Ein Modell kann ein perfekt geführtes Gespräch führen und dennoch den Konsolidierungsschritt verfehlen, indem es Prosa statt des Tool-Aufrufs zurückgibt, JSON bei einem langen Transkript kürzt oder ein Feld erfindet, das Ihr Schema nicht hat.
Warum die Konsolidierung durch ein einzelnes Modell fehlschlägt
Aufrufe mit strukturierter Ausgabe haben mehr Fehlerquellen als eine normale Chat-Vervollständigung:
- Das Modell ignoriert das Tool-Schema und gibt Prosa anstelle eines Tool-Aufrufs zurück.
- Der Anbieter gibt während einer Verkehrsspitze eine Ratenbegrenzung (429) oder einen Serverfehler (500/502/503) zurück.
- Die Anfrage überschreitet das Zeitlimit (Timeout), oft bei längeren Transkripten, deren Zusammenfassung mehr Tokens erfordert.
- Das Modell gibt gültiges JSON mit einem Feldnamen oder Typ zurück, der nicht mit Ihrem Schema übereinstimmt.
Jeder dieser Punkte verwandelt ein abgeschlossenes Gespräch in eine stille Gedächtnislücke. Dem Benutzer wird kein Fehler angezeigt. Er bemerkt es später, wenn der Agent etwas „vergessen“ hat, und bis dahin ist das rohe Transkript möglicherweise bereits gelöscht, wenn Sie es nicht separat gespeichert haben.
Wir haben keinen kontrollierten Benchmark für Ausfallraten für diese spezifische Laufzeit, Arbeitslast oder dieses Datum veröffentlicht, daher werden wir hier keinen spezifischen Prozentsatz nennen. Was überprüfbar ist, ist der Mechanismus: die vier oben genannten konkreten, benannten Fehlerquellen, die alle als Single Points of Failure eliminiert werden, sobald Sie Modelle verketten, anstatt nur eines aufzurufen.
Modellpreise für die Fallback-Kette
Die folgende Tabelle listet die aktuellen TokenLab-Preise für die in diesem Artikel beschriebenen Modelle der Fallback-Kette auf. Dies ist eine Live-Preisübersicht von TokenLab, die sich von den veröffentlichten Dokumentationen der Anbieter unterscheidet. Überprüfen Sie diese, bevor Sie eine Bestellung festlegen, da sich die Preise pro Token im Laufe der Zeit ändern.
| Modell | Kontextfenster | Input $/MTok | Output $/MTok | Quelle | Beobachtet |
|---|---|---|---|---|---|
| DeepSeek V4 Flash | 1.048.576 | $0,09 | $0,18 | TokenLab Live-Modell/Preisübersicht | 09.07.2026 |
| GLM-5.2 | 1.048.576 | $0,93 | $3,00 | TokenLab Live-Modell/Preisübersicht | 09.07.2026 |
| Qwen3.7 Plus | 1.000.000 | $0,32 | $1,28 | TokenLab Live-Modell/Preisübersicht | 09.07.2026 |
| Gemini 3.5 Flash | 1.048.576 | $1,50 | $9,00 | TokenLab Live-Modell/Preisübersicht | 09.07.2026 |
| GPT-5.5 | 1.050.000 | $5,00 | $30,00 | TokenLab Live-Modell/Preisübersicht | 09.07.2026 |
| Claude Sonnet 5 | 1.000.000 | $2,00 | $10,00 | TokenLab Live-Modell/Preisübersicht | 09.07.2026 |
| Claude Opus 4.8 | 1.000.000 | $5,00 | $25,00 | TokenLab Live-Modell/Preisübersicht | 09.07.2026 |
Für Live-Ratenbegrenzungen, aktuelle Preise und Zuverlässigkeitsrankings prüfen Sie das TokenLab-Modellverzeichnis und die Modell-Bestenliste, bevor Sie Ihre Kettenreihenfolge festlegen.
Wenn Sie den Datenverkehr zur Gedächtniskonsolidierung in der Produktion weiterleiten, starten Sie mit TokenLab, um alle sieben dieser Modelle über einen einzigen API-Schlüssel zu erreichen, anstatt separate Anmeldeinformationen, Ratenbegrenzungen und Fehlerformate pro Anbieter zu verwalten.
Die zweischichtige Fallback-Architektur
Schicht 1: kostengünstig, hohes Volumen, anbieterdivers
Diese Schicht läuft bei jedem Konsolidierungsereignis. Verketten Sie die Modelle über mindestens drei verschiedene Anbieter in dieser Reihenfolge:
- DeepSeek V4 Flash
- GLM-5.2
- Qwen3.7 Plus
- Gemini 3.5 Flash
- GPT-5.5
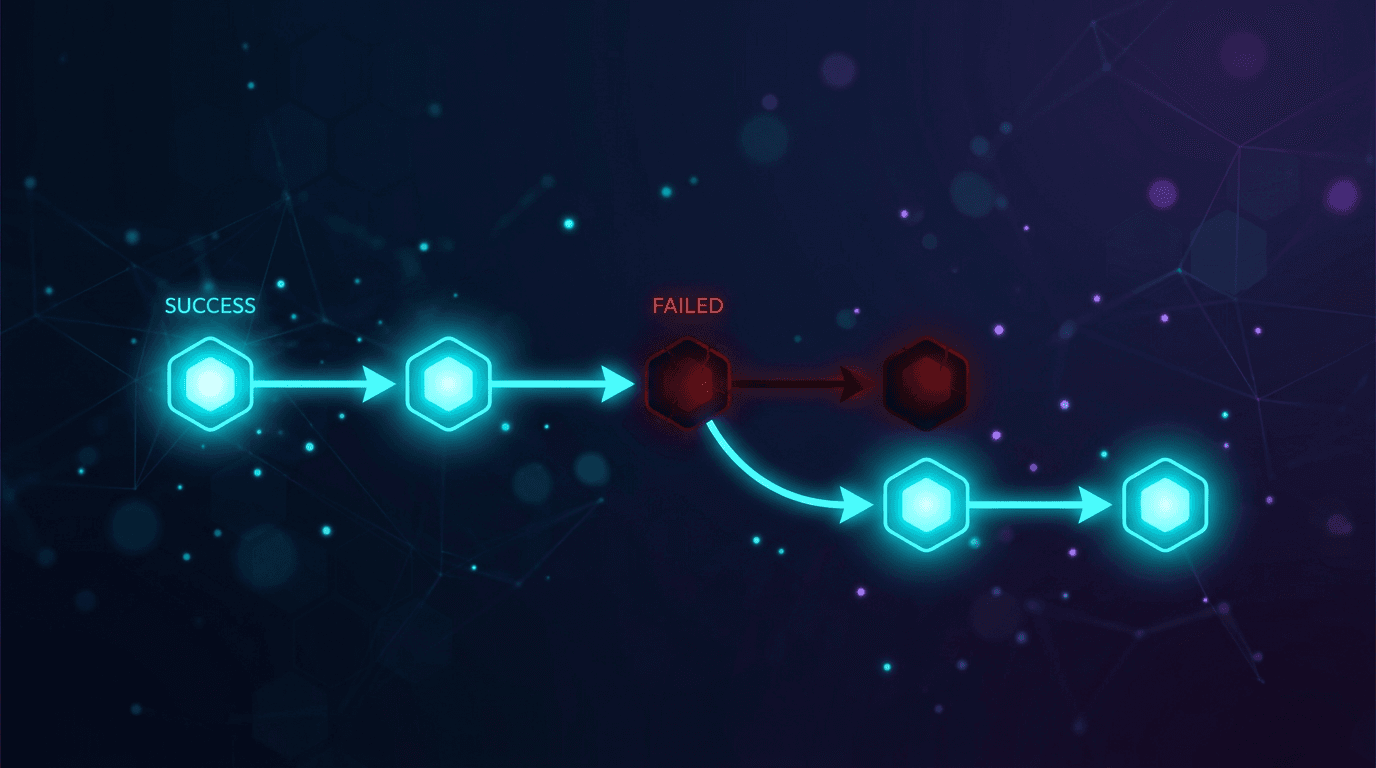
Bei jedem Fehler beim Tool-Aufruf, jeder Schemaverletzung, jedem Timeout oder jeder 4xx/5xx-Antwort gehen Sie sofort zum nächsten Modell in der Liste über. Wiederholen Sie nicht dasselbe Modell in Schicht 1; eine Ratenbegrenzung oder eine fehlerhafte Antwort tritt bei einem sofortigen erneuten Versuch eher wieder auf, als dass sie sich auflöst.
Schicht 2: Eskalation für echte Grenzfälle
Wenn jedes Modell der Schicht 1 fehlschlägt, eskalieren Sie auf ein stärkeres Modell, anstatt durch Schicht 1 zurückzuschleifen:
- Claude Sonnet 5
- Claude Opus 4.8 (letzter Fallback)
Schicht 2 sollte selten sein. Wenn Sie in Ihren Protokollen häufige Eskalationen auf Schicht 2 sehen, ist das ein Signal, Ihre Reihenfolge in Schicht 1, Ihre Schemastrenge oder Ihre Transkriptlänge zu überprüfen, kein Grund, Schicht 2 zu Ihrem Standardpfad zu machen.
Wie man eine asynchrone Hintergrund-Gedächtniskonsolidierung implementiert
Die Konsolidierung sollte niemals die nächste Nachricht des Benutzers blockieren. Führen Sie sie als Hintergrundjob aus, der beim Schließen der Sitzung oder bei einem Leerlauf-Timeout ausgelöst wird und in Ihren Gedächtnisspeicher schreibt, wenn er abgeschlossen ist, nicht inline im Chat-Antwortpfad. Diese Entkopplung macht auch die Worst-Case-Latenz einer Multi-Modell-Kette akzeptabel: Ein paar zusätzliche Sekunden für Wiederholungsversuche in einem Hintergrund-Worker haben keine Auswirkungen auf den benutzerseitigen Turn.
Der Kontrollfluss, ohne Code beschrieben, sieht wie folgt aus:
- Beim Schließen der Sitzung oder bei einem Leerlauf-Timeout wird ein Hintergrundjob mit dem vollständigen Transkript in die Warteschlange gestellt.
- Der Worker versucht die Konsolidierung mit dem ersten Modell in der Liste der Schicht 1, mit einem begrenzten Timeout pro Versuch.
- Bei einem Timeout, 429 oder 5xx geht der Worker sofort zum nächsten Modell in der Liste über, ohne einen direkten erneuten Versuch mit demselben Modell.
- Bei einer 200-Antwort validiert der Worker die Nutzlast anhand Ihres JSON-Schemas, bevor er sie akzeptiert. Eine Antwort, die die HTTP-Statusprüfung besteht, aber bei der Schema-Validierung fehlschlägt, wird wie ein Netzwerkfehler behandelt: Protokollieren Sie ihn und gehen Sie zum nächsten Modell über.
- Wenn jedes Modell der Schicht 1 fehlschlägt, eskaliert der Worker auf Schicht 2 (Claude Sonnet 5, dann Claude Opus 4.8) unter Verwendung derselben Timeout-und-Validierungslogik.
- Wenn jedes Modell in beiden Schichten fehlschlägt, speichert der Worker das rohe, unkonsolidierte Transkript im Speicher und alarmiert einen On-Call-Ingenieur. Das rohe Transkript wird niemals verworfen, unabhängig davon, wie die Konsolidierung ausgeht.
- Protokollieren Sie, welches Modell jedes Ereignis aufgelöst hat (oder dass die gesamte Kette fehlgeschlagen ist), damit Sie Ihre eigene Auflösungsrate für Schicht 1 messen und die Kette später neu ordnen können.
Wir veröffentlichen kein kopierbares Codebeispiel mit spezifischen SDK-Methodennamen, Anforderungsnutzlasten oder Antwortformen für diese sieben Anbieter, da dieser Datensatz keine verifizierten Endpunkt-, Auth- und Nutzlastdetails für jeden einzelnen enthält und deren Erfindung Integrationscode erzeugen würde, der korrekt aussieht, aber in der Produktion stillschweigend fehlschlägt. Bevor Sie diesen Ablauf implementieren, arbeiten Sie die unten stehende Verifizierungs-Checkliste anhand der Dokumentation jedes Anbieters durch.
Verifizierungs-Checkliste vor der Implementierung
- Bestätigen Sie den aktuellen Endpunkt, das Auth-Header-Format und die Form des Anforderungskörpers für den Modus der strukturierten Ausgabe oder des Tool-Aufrufs jedes Anbieters direkt aus deren offizieller API-Referenz, nicht aus einer Zusammenfassung von Drittanbietern.
- Bestätigen Sie, welches Ausnahme- oder Fehlerobjekt das SDK jedes Anbieters für 429, 500/502/503 und clientseitige Timeouts auslöst, da diese je nach SDK unterschiedlich sind und sich über SDK-Versionen hinweg ändern.
- Bestätigen Sie, ob die Client-Bibliothek jedes Anbieters einen eingebauten Wiederholungsmechanismus hat, den Sie deaktivieren müssen, da Sie in dieser Kette ein Failover zwischen Anbietern wünschen, keine bibliotheksinterne Wiederholung für dasselbe Modell.
- Bestätigen Sie, dass Ihr JSON-Schema-Validator bei jeder Antwort läuft, bevor sie
persist_memoryerreicht, einschließlich Antworten, die HTTP 200 zurückgeben. - Wenn Sie über ein Multi-Anbieter-Gateway wie TokenLab routen, anstatt jeden Anbieter direkt aufzurufen, bestätigen Sie das eigene Fehler-Passthrough-Format des Gateways in dessen Dokumentation unter tokenlab.sh/en/models, bevor Sie davon ausgehen, dass anbieterspezifische Fehlercodes unverändert weitergegeben werden.
Hinweise zur Fehlerbehandlung, zugeordnet zu echten Fehlerklassen
| Fehlerklasse | Behandlung |
|---|---|
| 429 Ratenbegrenzung | Gehen Sie sofort zum nächsten Modell über. Wiederholen Sie nicht dasselbe Modell in der Schleife. Wenn ein Modell wiederholt Ratenbegrenzungen auslöst, fügen Sie eine kurze Abkühlphase hinzu, bevor es bei zukünftigen Aufrufen erneut versucht wird. |
| 500/502/503 Serverfehler | Als vorübergehend behandeln. Gehen Sie zum nächsten Modell über. Fügen Sie innerhalb dieser Kette kein exponentielles Backoff hinzu; ein Failover auf einen anderen Anbieter ist schneller, als den Ausfall eines Anbieters abzuwarten. |
| Timeout | Begrenzen Sie jeden Versuch (eine illustrative Grenze von 5-10 Sekunden pro Aufruf; passen Sie dies an Ihre Transkriptlänge an). Gehen Sie bei einem Timeout zum nächsten Modell über, anstatt die Wartezeit zu verlängern. |
| 4xx außer 429 | Normalerweise ein Fehler im Anforderungsformat auf Ihrer Seite. Protokollieren Sie dies lautstark und alarmieren Sie einen Menschen; lassen Sie es nicht ewig stillschweigend fehlschlagen, ohne Sichtbarkeit. |
| 200 OK mit fehlerhaftem Körper | Validieren Sie anhand Ihres JSON-Schemas, bevor Sie es akzeptieren. Eine syntaktisch gültige Antwort mit der falschen Form ist immer noch ein Fehler und muss durch Validierung abgefangen werden, nicht nur durch den HTTP-Status. |
Zum Einwand „Führt dies zur Erschöpfung der Ratenbegrenzung“: Jedes Modell der Schicht 1 sitzt hinter einem anderen Anbieter, sodass eine 429 bei einem Anbieter nicht das Kontingent eines anderen Anbieters verbraucht. Die Kette verteilt die Last, anstatt sie zu konzentrieren. Im schlimmsten Fall sind fünf Versuche der Schicht 1 plus zwei Versuche der Schicht 2 sieben Aufrufe; bei einer Timeout-Grenze von 8 Sekunden pro Versuch begrenzt dies den schlimmsten Fall auf etwa eine Minute, und dieses Szenario erfordert, dass jeder Anbieter gleichzeitig ausfällt, was der seltene Grenzfall ist, für den dieses Design gebaut wurde, nicht der übliche Pfad. Dies ist eine Grenze, die auf den von Ihnen konfigurierten Timeouts basiert, kein gemessener Produktions-Latenz-Benchmark; wir haben diese Kette nicht unter Last ausgeführt und berichten keinen gemessenen p50/p99.
Illustrativer Kostenvergleich über die Fallback-Kette
Um zu zeigen, warum das Routing des Großteils des Volumens über kostengünstige Modelle wichtig ist, finden Sie hier ein Beispiel unter Verwendung der obigen Preistabelle. Annahme: Ein durchschnittlicher Konsolidierungsaufruf sendet ein 3.000-Token-Transkript als Input und erzeugt 400 Tokens strukturierte Ausgabe. Dies ist eine illustrative Annahme, kein gemessener Durchschnitt aus einer spezifischen Kundenarbeitslast; ersetzen Sie dies durch Ihre eigenen Token-Anzahlen.
| Modell | Kosten pro Aufruf (obige Annahme) |
|---|---|
| DeepSeek V4 Flash | $0,00034 |
| Qwen3.7 Plus | $0,00147 |
| GLM-5.2 | $0,00399 |
| Gemini 3.5 Flash | $0,00810 |
| Claude Sonnet 5 | $0,01000 |
| Claude Opus 4.8 | $0,02500 |
| GPT-5.5 | $0,02700 |
Die Spanne ist real: Das Routing von 100 % der Aufrufe über GPT-5.5 kostet unter dieser Annahme etwa 80-mal mehr pro Aufruf als das Routing über DeepSeek V4 Flash. Was wir ohne Ihre eigenen Daten nicht angeben können, ist, welcher Teil Ihres Datenverkehrs tatsächlich auf Schicht 1 aufgelöst wird, im Vergleich zur Eskalation auf Schicht 2, da dies von Ihrer Transkriptlänge, der Schemakomplexität und der Zuverlässigkeit des Anbieters an dem Tag abhängt, an dem Sie es ausführen. Protokollieren Sie, welches Modell jedes Ereignis auflöst (Schritt 7 im Implementierungsablauf oben), und berechnen Sie Ihre eigenen Mischkosten nach ein paar tausend Ereignissen, anstatt sich auf einen geliehenen Prozentsatz zu verlassen.
Einschränkungen
- Es existiert kein öffentlicher, reproduzierbarer Benchmark für Ausfallraten für diese spezifische Kette, Arbeitslast oder dieses Datum in diesem Datensatz. Instrumentieren Sie die Protokollierung in Ihrer eigenen Laufzeit, bevor Sie eine spezifische Zahl nennen.
- Die Kostentabelle oben verwendet eine angenommene Token-Anzahl, keine gemessene durchschnittliche Transkriptlänge. Berechnen Sie dies mit Ihren eigenen Zahlen unter Verwendung der Quelle und des beobachteten Datums der Preistabelle neu.
- Modellpreise und Kontextfenster ändern sich. Bestätigen Sie die aktuellen Werte im TokenLab-Modellverzeichnis, bevor Sie eine Kettenreihenfolge für die Produktion festlegen.
- Eine Fallback-Kette reduziert das Risiko eines Single Point of Failure; sie garantiert keinen Datenverlust von Null. Speichern Sie das rohe Transkript immer separat von der strukturierten Konsolidierungsausgabe.
- Latenz- und Ratenbegrenzungs-Erschöpfungszahlen in diesem Artikel sind Schätzungen, die auf konfigurierbaren Timeouts basieren, keine gemessenen Produktions-Benchmarks. Wir haben diese Kette in diesem Datensatz nicht unter Last ausgeführt.
- Dieser Artikel enthält absichtlich keinen kopierbaren Anforderungscode, da exakte Endpunkt-, Auth-Header- und Nutzlastnachweise für diese sieben Anbieter zum Zeitpunkt des Schreibens nicht verifizierbar waren. Verwenden Sie die Verifizierungs-Checkliste und die offiziellen Dokumente jedes Anbieters, bevor Sie implementieren.
Implementierungs-Checkliste
| Praxis | Warum es wichtig ist |
|---|---|
| Schema validieren, nicht nur HTTP-Status | Eine 200-Antwort mit fehlerhaftem JSON oder einem fehlenden Tool-Aufruf ist immer noch ein Fehler, den Ihre Wiederholungslogik abfangen muss. |
| Timeout pro Versuch begrenzen | Begrenzen Sie die Worst-Case-Wanduhrzeit, damit ein langsamer Anbieter nicht den gesamten Hintergrundjob blockiert. |
| Failover über Anbieter hinweg, nicht innerhalb eines | Eine 429 oder 503 bei einem Anbieter sollte sofort zu einem anderen Anbieter führen, anstatt denselben erneut zu versuchen. |
| Protokollieren, welches Modell jedes Ereignis aufgelöst hat | So messen Sie Ihre eigene Auflösungsrate für Schicht 1 und ordnen die Kette neu, wenn sich Preise und Zuverlässigkeit ändern. |
| Niemals das rohe Transkript verwerfen | Speichern Sie das rohe Gespräch auch bei einem vollständigen Kettenausfall. Eine fehlgeschlagene strukturierte Zusammenfassung ist wiederherstellbar; ein gelöschtes Transkript nicht. |
| Bei Nicht-429/503 4xx-Fehlern alarmieren | Diese deuten normalerweise auf einen Schema- oder Anforderungsfehler auf Ihrer Seite hin, nicht auf ein vorübergehendes Anbieterproblem, und sollten nicht ewig stillschweigend wiederholt werden. |
| SDK-Fehlertypen pro Anbieter vor dem Deployment verifizieren | Ausnahmeklassen für 429, 5xx und Timeouts unterscheiden sich je nach Anbieter-SDK und ändern sich zwischen SDK-Versionen; prüfen Sie die aktuellen Dokumente, anstatt Annahmen zu treffen. |
Für Routing-Entscheidungen auf Anbieterebene jenseits einzelner Modelle behandelt der OpenRouter-Vergleich, wie sich Multi-Anbieter-Routing auf das Ratenbegrenzungs- und Failover-Verhalten auswirkt.
FAQ
Was ist die Konsolidierung des AI-Agent-Gedächtnisses?
Der Hintergrundprozess, der ein rohes Gesprächstranskript in strukturiertes, dauerhaftes Gedächtnis (Fakten, Präferenzen, Entscheidungen) umwandelt, das in den Langzeitspeicher geschrieben wird, normalerweise über einen erzwungenen Tool-Aufruf oder eine JSON-Modus-Vervollständigung am Ende der Sitzung.
Wie implementiere ich eine asynchrone Hintergrund-Gedächtniskonsolidierung, ohne den Chat zu blockieren?
Lösen Sie sie beim Schließen der Sitzung oder bei einem Leerlauf-Timeout als Hintergrund-Worker-Job aus, getrennt vom Chat-Antwortpfad. Der Worker schreibt in Ihren Gedächtnisspeicher, wenn er fertig ist; die nächste Nachricht des Benutzers wartet nicht darauf. Dies macht auch die Latenz bei Wiederholungsversuchen mit mehreren Modellen akzeptabel, da sie außerhalb des kritischen Pfads stattfindet.
Verursacht eine 5-7-Modell-Wiederholungskette Latenz- oder Ratenbegrenzungsprobleme?
Das Latenzrisiko ist durch Ihr Timeout pro Versuch begrenzt und wird durch die asynchrone Ausführung der Konsolidierung absorbiert. Das Risiko der Ratenbegrenzung wird gemindert, da die Kette über verschiedene Anbieter hinweg ausweicht, anstatt einen Anbieter wiederholt abzufragen, sodass eine 429 bei einem Modell nicht das Kontingent eines anderen Anbieters belastet oder erschöpft. Dies sind architektonische Minderungsmaßnahmen, keine gemessenen Latenzzahlen; wir haben diese Kette nicht unter Produktionslast gebenchmarkt.
Welches Modell sollte die Gedächtniskonsolidierung standardmäßig übernehmen?
Beginnen Sie mit dem günstigsten zuverlässigen Modell für Ihr Volumen, wie DeepSeek V4 Flash, und verketten Sie vier oder fünf Modelle über verschiedene Anbieter hinweg dahinter als Schicht 1. Reservieren Sie Claude Sonnet 5 und Claude Opus 4.8 nur als Eskalation für Schicht 2. Überprüfen Sie die aktuellen Preise im TokenLab-Modellverzeichnis, bevor Sie die Reihenfolge festlegen.
Was passiert, wenn jedes Modell in der Fallback-Kette fehlschlägt?
Speichern Sie das rohe Transkript unkonsolidiert, anstatt es zu verwerfen, alarmieren Sie einen Menschen und prüfen Sie, ob das Transkript selbst (Länge, Format, Kodierung) den Fehler bei jedem Anbieter auslöst, da eine gemeinsame Ursache wahrscheinlicher ist als sieben unabhängige Ausfälle.
Woher weiß ich, ob dies meine Kosten tatsächlich senkt?
Protokollieren Sie, welche Schicht jedes Konsolidierungsereignis auflöst, und berechnen Sie die Mischkosten aus Ihren eigenen Daten unter Verwendung der obigen Preistabelle pro Modell. Verlassen Sie sich nicht auf einen geliehenen Prozentsatz; Ihre Auflösungsrate hängt von Ihrer Transkriptlänge, der Schemastrenge und der Zuverlässigkeit des Anbieters ab.
Warum enthält dieser Artikel keinen funktionierenden API-Code?
Da dieser Datensatz keine verifizierten aktuellen Endpunkt-, Auth- und Nutzlastdetails für alle sieben Anbieter in der Kette enthält, wäre die Veröffentlichung von plausibel aussehendem, aber unverifiziertem Anforderungscode schlimmer als gar kein Code. Verwenden Sie die obige Verifizierungs-Checkliste anhand der offiziellen API-Referenz jedes Anbieters, bevor Sie Ihre Integration schreiben.
Erste Schritte
Wenn Sie ein Agenten-Gedächtnis aufbauen, das es sich nicht leisten kann, Kontext stillschweigend zu verlieren, starten Sie mit TokenLab, um aktuelle Preise zu vergleichen und Konsolidierungsdatenverkehr über die Modelle in dieser Fallback-Kette über einen einzigen API-Schlüssel zu routen, anstatt separate Anmeldeinformationen und Ratenbegrenzungen pro Anbieter zu verwalten.
Quellen
Preis geprüft am 2026-07-07
- fal PixVerse V6 model pageGeprüft am 2026-07-09
- fal FLUX.2 model pageGeprüft am 2026-07-09
- TokenLab model directoryGeprüft am 2026-07-07