ユーザーがエージェントとの30分間のセッションを終えます。ユーザーは要件を伝え、好みを述べ、決定を下しました。しかし、新しいセッションを開始すると、それらの情報は一切引き継がれません。通常、この問題の原因はエージェントの推論能力ではなく、AIエージェントのメモリ統合(Memory Consolidation)にあります。これは、生のトランスクリプトを構造化された長期記憶へと変換するバックグラウンド処理です。このステップは単一のモデルに対する単一のAPIコールであり、単一のAPIコールは失敗する可能性があります。レート制限、タイムアウト、不正なツール出力などはすべて同じ症状を引き起こします。つまり、ユーザーにエラーが表示されることなく、静かにメモリが失われるのです。
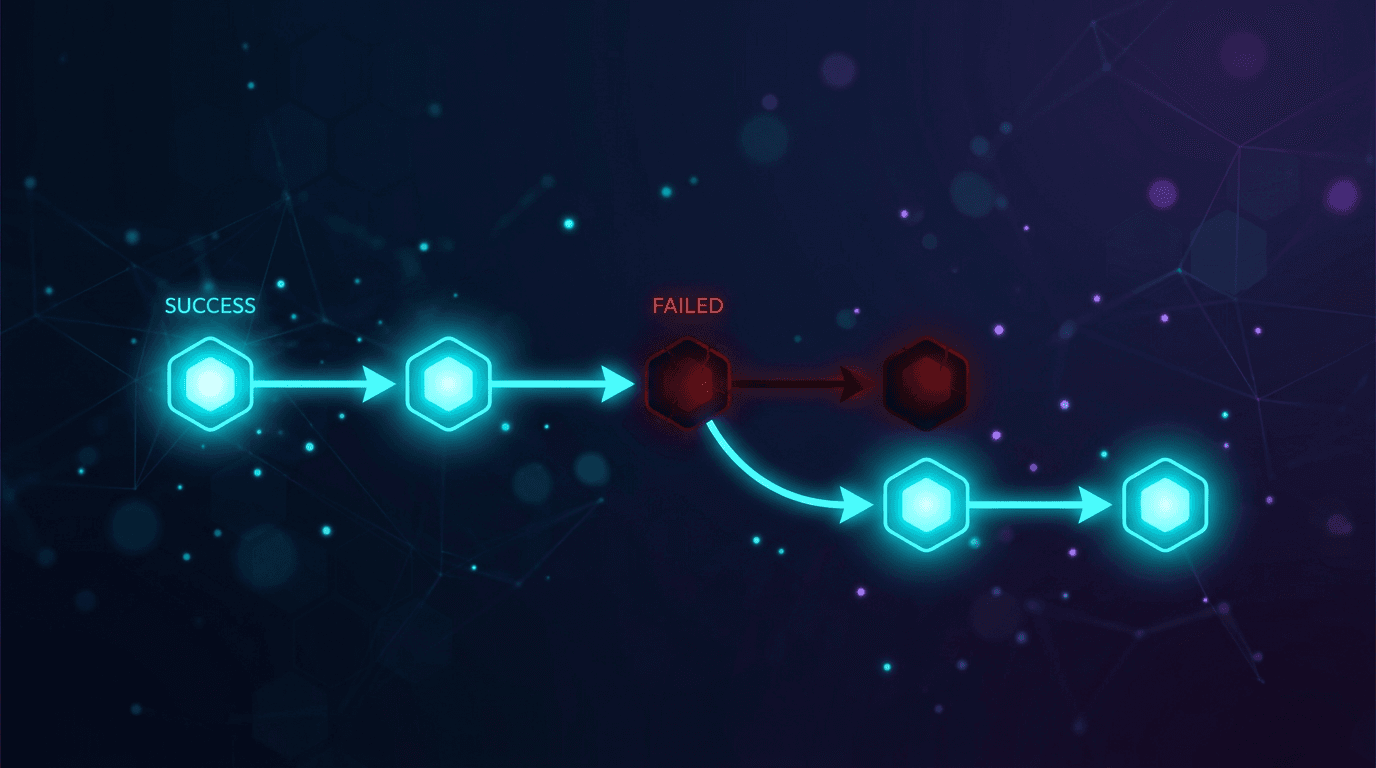
この記事で紹介する解決策は、プロンプトを改善することではなく、アーキテクチャを変更することです。統合処理を単一のモデルではなく、モデルの順序付きチェーンを通じて実行することで、特定のプロバイダーで障害が発生しても会話データが削除されないようにします。
メモリサブシステムだけでなく、周辺のプロダクトインターフェースを構築している場合は、本ページと併せてワンキー・チャットボットガイドおよびAI APIレート制限ガイドを参照してください。個別のモデルではなくプロバイダーを比較したい場合は、本記事と併せてOpenRouter比較記事をお読みください。
重要なポイント
- メモリ統合は、構造化出力(ツールコールまたは強制JSON)を伴う限定的なタスクであり、自由形式のチャットよりもスキーマ違反、切り捨て、レート制限、タイムアウトといった失敗モードが多く存在します。
- 統合処理を単一のモデルに依存させることは、単一障害点(SPOF)となります。統合処理はプロンプトエンジニアリングの問題ではなく、フォールバックチェーンを備えた信頼性の問題として扱うべきです。
- 2層構造のチェーンが実用的です。第1層は低コストモデル(DeepSeek V4 Flash、GLM-5.2、Qwen3.7 Plus、Gemini 3.5 Flash、GPT-5.5)のシーケンスで、エラー発生時に相互にフェイルオーバーします。第2層は、第1層のすべてのモデルが失敗した場合にのみ、Claude Sonnet 5、次いでClaude Opus 4.8へとエスカレーションします。
- 本記事には、この特定のランタイムに対する公開された再現可能な失敗率やコスト削減率は記載されていません。以下の価格計算は例示であり、その旨を明記しています。数値を引用する前に、自身のワークロードで測定を行ってください。
- このチェーンは単一のプロバイダーを繰り返し再試行するのではなく、独立したプロバイダー間でフェイルオーバーするため、単一のレート制限に負荷が集中することはありません。また、統合処理は非同期のバックグラウンドジョブとして実行されるため、再試行による遅延がユーザー向けのチャット応答をブロックすることはありません。
AIエージェントのメモリ統合とは何か?
メモリ統合とは、生の会話トランスクリプトを、ユーザーの好み、決定事項、プロジェクトの状態、言及されたエンティティなどの構造化された永続的な事実へと変換するプロセスです。これは、現在のセッションのメッセージを保持するエージェントのアクティブなコンテキストウィンドウとは異なります。統合処理は通常、セッションごとに(終了時、アイドルタイムアウト時、またはローリングウィンドウごとに)1回実行され、その出力をチャットに戻すのではなく、データベース、ベクトルストア、またはメモリサービスに書き込みます。
出力はスキーマに一致する必要があるため(後続の取得コードがそれを利用できるようにするため)、統合処理は通常、単純なチャット返信ではなく、強制的なツールコールやJSONモードの補完として実装されます。これが脆弱性の原因です。モデルは完璧な会話を維持できていても、ツールコールではなく散文を返したり、長いトランスクリプトでJSONを切り捨てたり、スキーマにないフィールドを捏造したりすることで、統合ステップに失敗する可能性があるからです。
単一モデルによる統合が失敗する理由
構造化出力の呼び出しには、通常のチャット補完よりも多くの失敗モードがあります:
- モデルがツールスキーマを無視し、ツールコールではなく散文を返す。
- トラフィックの急増時に、プロバイダーがレート制限(429)やサーバーエラー(500/502/503)を返す。
- リクエストがタイムアウトする(多くの場合、トークン消費量が多い長いトランスクリプトで発生)。
- モデルが有効なJSONを返すが、スキーマと一致しないフィールド名や型が含まれている。
これらのいずれかが発生すると、完了したはずの会話が静かなメモリの欠落に変わります。ユーザーにはエラーが表示されません。ユーザーが後でエージェントが何かを「忘れた」ことに気づいたときには、別途永続化していなければ、生のトランスクリプトはすでに失われている可能性があります。
本記事では、この特定のランタイム、ワークロード、日付に対する管理された失敗率のベンチマークを公開していないため、特定の数値を再提示することはしません。検証可能なのはそのメカニズムです。上記の4つの具体的かつ明確な失敗モードは、単一のモデルを呼び出す代わりにモデルをチェーンさせることで、すべて単一障害点から排除されます。
フォールバックチェーンのモデル価格
以下の表は、本記事で説明するフォールバックチェーンで使用されるモデルの現在のTokenLab価格です。これはTokenLabのライブ価格スナップショットであり、プロバイダーが公開しているドキュメントとは異なります。トークンあたりの価格は時間とともに変化するため、注文を確定する前に必ず確認してください。
| モデル | コンテキストウィンドウ | 入力 $/MTok | 出力 $/MTok | ソース | 観測日 |
|---|---|---|---|---|---|
| DeepSeek V4 Flash | 1,048,576 | $0.09 | $0.18 | TokenLab ライブモデル/価格スナップショット | 2026-07-09 |
| GLM-5.2 | 1,048,576 | $0.93 | $3.00 | TokenLab ライブモデル/価格スナップショット | 2026-07-09 |
| Qwen3.7 Plus | 1,000,000 | $0.32 | $1.28 | TokenLab ライブモデル/価格スナップショット | 2026-07-09 |
| Gemini 3.5 Flash | 1,048,576 | $1.50 | $9.00 | TokenLab ライブモデル/価格スナップショット | 2026-07-09 |
| GPT-5.5 | 1,050,000 | $5.00 | $30.00 | TokenLab ライブモデル/価格スナップショット | 2026-07-09 |
| Claude Sonnet 5 | 1,000,000 | $2.00 | $10.00 | TokenLab ライブモデル/価格スナップショット | 2026-07-09 |
| Claude Opus 4.8 | 1,000,000 | $5.00 | $25.00 | TokenLab ライブモデル/価格スナップショット | 2026-07-09 |
ライブのレート制限、最新の価格、信頼性ランキングについては、チェーンの順序を確定する前にTokenLabモデルディレクトリおよびモデルリーダーボードを確認してください。
プロダクション環境でメモリ統合トラフィックをルーティングする場合は、TokenLabの利用を開始してください。プロバイダーごとに個別の認証情報、レート制限、エラー形式を管理する代わりに、単一のAPIキーを通じてこれら7つのモデルすべてにアクセスできます。
2層フォールバックアーキテクチャ
第1層:安価、大容量、プロバイダー多様性
この層はすべての統合イベントで実行されます。少なくとも3つの異なるプロバイダーにまたがって、以下の順序でモデルをチェーンさせます:
- DeepSeek V4 Flash
- GLM-5.2
- Qwen3.7 Plus
- Gemini 3.5 Flash
- GPT-5.5
ツールコールの失敗、スキーマ違反、タイムアウト、または4xx/5xx応答が発生した場合は、直ちにリスト内の次のモデルへ移行してください。第1層では同じモデルを再試行しないでください。レート制限や不正な応答は、即時の再試行で解決するよりも繰り返される可能性の方が高いためです。
第2層:真のエッジケースのためのエスカレーション
第1層のすべてのモデルが失敗した場合は、第1層をループするのではなく、より強力なモデルへエスカレーションします:
- Claude Sonnet 5
- Claude Opus 4.8(最終フォールバック)
第2層への移行は稀であるべきです。ログで頻繁に第2層へのエスカレーションが発生している場合は、第2層をデフォルトのパスにするのではなく、第1層の順序、スキーマの厳密さ、またはトランスクリプトの長さを確認するシグナルです。
非同期バックグラウンドメモリ統合の実装方法
統合処理がユーザーの次のメッセージをブロックしてはなりません。セッション終了時やアイドルタイムアウト時にトリガーされるバックグラウンドジョブとして実行し、チャット応答パスにインラインで含めるのではなく、完了時にメモリストアへ書き込むようにします。この分離こそが、マルチモデルチェーンの最悪の遅延を許容可能にする理由でもあります。バックグラウンドワーカーでの数秒の再試行は、ユーザー向けのチャットターンには影響を与えません。
コードを除いた制御フローは以下の通りです:
- セッション終了時またはアイドルタイムアウト時に、完全なトランスクリプトを含むバックグラウンドジョブをエンキューします。
- ワーカーは、試行ごとのタイムアウト制限を設けた上で、第1層リストの最初のモデルに対して統合を試みます。
- タイムアウト、429、または5xxが発生した場合、ワーカーは同じモデルに対するその場での再試行を行わず、直ちにリスト内の次のモデルへ移行します。
- 200応答を受け取った場合、ワーカーは受け入れる前にJSONスキーマに対してペイロードを検証します。HTTPステータスチェックには合格してもスキーマ検証に失敗した応答は、ネットワーク障害と同じ扱いとし、ログに記録して次のモデルへ移行します。
- 第1層のすべてのモデルが失敗した場合、ワーカーは同じタイムアウトおよび検証ロジックを使用して、第2層(Claude Sonnet 5、次いでClaude Opus 4.8)へエスカレーションします。
- 両層のすべてのモデルが失敗した場合、ワーカーは統合されていない生のトランスクリプトをストレージに永続化し、オンコールエンジニアにアラートを送信します。生のトランスクリプトは、統合の結果に関わらず決して破棄されません。
- 各イベントをどのモデルが解決したか(あるいはチェーン全体が失敗したか)をログに記録し、第1層の解決率を測定して後でチェーンの順序を再調整できるようにします。
本記事では、これら7つのプロバイダーの具体的なSDKメソッド名、リクエストペイロード、応答形状を含むコピー&ペースト可能なコードサンプルは公開していません。この証拠セットには各プロバイダーの検証済みエンドポイント、認証、ペイロード詳細が含まれておらず、それらを捏造すると、一見正しく見えるがプロダクションで静かに失敗する統合コードが生成されてしまうためです。このフローを実装する前に、各プロバイダーの公式ドキュメントと照らし合わせて以下の検証チェックリストを確認してください。
実装前の検証チェックリスト
- 各プロバイダーの構造化出力またはツール呼び出しモードのエンドポイント、認証ヘッダー形式、リクエストボディの形状を、サードパーティの要約ではなく、公式のAPIリファレンスから直接確認してください。
- 各プロバイダーのSDKが429、500/502/503、およびクライアント側のタイムアウトに対してどのような例外やエラーオブジェクトを発生させるかを確認してください。これらはSDKやバージョンによって異なります。
- 各プロバイダーのクライアントライブラリに、無効にする必要のある組み込みの再試行メカニズムがあるかどうかを確認してください。このチェーンではライブラリ内での再試行ではなく、プロバイダーをまたいだフェイルオーバーを求めているためです。
- JSONスキーマバリデーターが、HTTP 200を返す応答を含め、
persist_memoryに到達する前のすべての応答に対して実行されることを確認してください。 - 各プロバイダーを直接呼び出すのではなく、TokenLabのようなマルチプロバイダーゲートウェイを経由する場合は、プロバイダー固有のエラーコードが変更されずに伝搬すると想定する前に、tokenlab.sh/en/modelsにあるゲートウェイ独自のエラーパススルー形式を確認してください。
エラーハンドリングの注記(実際の失敗クラスへのマッピング)
| エラークラス | ハンドリング |
|---|---|
| 429 レート制限 | 直ちに次のモデルへ移行します。ループ内で同じモデルを再試行しないでください。特定のモデルでレート制限が繰り返される場合は、将来の呼び出しで試行される前に短いクールダウンを追加します。 |
| 500/502/503 サーバーエラー | 一時的なものとして扱います。次のモデルへ移行します。このチェーン内で指数バックオフを追加しないでください。プロバイダーの停止を待つよりも、別のプロバイダーへフェイルオーバーする方が高速です。 |
| タイムアウト | 各試行に上限を設けます(呼び出しごとに5〜10秒の例示的な制限。トランスクリプトの長さに合わせて調整してください)。タイムアウト時は待機時間を延長するのではなく、次のモデルへ移行します。 |
| 429以外の4xx | 通常はユーザー側のリクエスト形式のバグです。大きくログに記録して人間にアラートを出してください。可視性なしに永久に静かにフェイルオーバーさせないでください。 |
| 200 OKだがボディが不正 | 受け入れる前にJSONスキーマに対して検証します。構文的に有効でも形状が間違っている応答は失敗であり、HTTPステータスだけでなく検証によってキャッチする必要があります。 |
「これによりレート制限が枯渇するのではないか」という懸念について:各第1層モデルは異なるプロバイダーの背後に存在するため、一方での429が別のプロバイダーのクォータを消費することはありません。このチェーンは負荷を集中させるのではなく、分散させます。最悪の場合、第1層の5回の試行と第2層の2回の試行で合計7回の呼び出しとなります。試行ごとに8秒のタイムアウト制限を設けた場合、最悪のケースでも1分程度に収まります。このシナリオにはすべてのプロバイダーが同時に失敗する必要がありますが、これは本設計が生き残るために構築された稀なエッジケースであり、一般的なパスではありません。これは設定したタイムアウトに基づく上限であり、測定されたプロダクション遅延ベンチマークではありません。本チェーンを負荷下で実行したことはなく、測定されたp50/p99を報告しているわけではありません。
フォールバックチェーンのコスト比較例
ほとんどのボリュームを安価なモデルでルーティングすることがなぜ重要かを示すため、上記の価格表を使用した計算例を挙げます。前提:平均的な統合呼び出しは、入力として3,000トークンのトランスクリプトを送信し、400トークンの構造化出力を生成する。これは例示的な前提であり、特定の顧客ワークロードから測定された平均ではありません。自身のトークン数に置き換えてください。
| モデル | 呼び出しあたりのコスト(上記の前提) |
|---|---|
| DeepSeek V4 Flash | $0.00034 |
| Qwen3.7 Plus | $0.00147 |
| GLM-5.2 | $0.00399 |
| Gemini 3.5 Flash | $0.00810 |
| Claude Sonnet 5 | $0.01000 |
| Claude Opus 4.8 | $0.02500 |
| GPT-5.5 | $0.02700 |
この差は現実的です。この前提の下では、すべての呼び出しをGPT-5.5経由でルーティングすると、DeepSeek V4 Flash経由でルーティングするよりも呼び出しあたり約80倍のコストがかかります。自身のデータなしに断言できないのは、トランスクリプトの長さ、スキーマの複雑さ、実行日のプロバイダーの信頼性に依存するため、トラフィックの何割が実際に第1層で解決し、何割が第2層へエスカレーションするかという点です。各イベントをどのモデルが解決したかをログに記録し(実装フローのステップ7)、数千件のイベント後に自身のブレンドコストを計算してください。借り物のパーセンテージに頼ってはいけません。
制限事項
- この証拠セットには、この特定のチェーン、ワークロード、日付に対する公開された再現可能な失敗率のベンチマークは存在しません。特定の数値を引用する前に、自身のランタイムでログを計測してください。
- 上記のコスト表は、測定された平均トランスクリプト長ではなく、想定されたトークン数を使用しています。価格表のソースと観測日を使用して、自身の数値で再計算してください。
- モデルの価格とコンテキストウィンドウは変更されます。プロダクション用のチェーン順序を確定する前に、TokenLabモデルディレクトリで現在の値を確認してください。
- フォールバックチェーンは単一障害点のリスクを軽減しますが、データ損失ゼロを保証するものではありません。生のトランスクリプトは、構造化された統合出力とは別に常に永続化してください。
- 本記事の遅延およびレート制限枯渇の数値は、設定可能なタイムアウトに基づく推定値であり、測定されたプロダクションベンチマークではありません。本証拠セットにおいて、このチェーンを負荷下で実行したことはありません。
- 本記事にはコピー&ペースト可能なリクエストコードを意図的に含めていません。これら7つのプロバイダーの正確なエンドポイント、認証ヘッダー、ペイロードの証拠を執筆時点で検証できなかったためです。実装前に検証チェックリストと各プロバイダーの公式ドキュメントを使用してください。
実装チェックリスト
| プラクティス | 重要性 |
|---|---|
| HTTPステータスだけでなくスキーマを検証する | 不正なJSONやツールコールの欠落を伴う200応答は、再試行ロジックでキャッチすべき失敗です。 |
| 試行ごとのタイムアウトに上限を設ける | 1つの低速なプロバイダーがバックグラウンドジョブ全体を停滞させないよう、最悪のケースの壁時計時間を制限します。 |
| プロバイダーをまたいでフェイルオーバーする | あるプロバイダーでの429や503は、同じプロバイダーを再試行するのではなく、直ちに別のプロバイダーへルーティングすべきです。 |
| 各イベントをどのモデルが解決したかログに記録する | これにより、自身の第1層解決率を測定し、価格や信頼性の変化に応じてチェーンを再順序付けできます。 |
| 生のトランスクリプトを絶対に破棄しない | チェーン全体が失敗した場合でも、生の会話を永続化してください。失敗した構造化要約は復旧可能ですが、削除されたトランスクリプトは復旧できません。 |
| 429/503以外の4xxエラーでアラートを出す | これらは通常、一時的なプロバイダーの問題ではなく、ユーザー側のスキーマやリクエストのバグを示しており、永久に静かに再試行されるべきではありません。 |
| デプロイ前にプロバイダーごとのSDKエラー型を検証する | 429、5xx、タイムアウトの例外クラスはプロバイダーのSDK間で異なり、SDKバージョン間でも変化します。想定せず現在のドキュメントを確認してください。 |
個別のモデルを超えたプロバイダーレベルのルーティング決定については、OpenRouter比較記事で、マルチプロバイダールーティングがレート制限やフェイルオーバーの動作をどのように変えるかを解説しています。
よくある質問(FAQ)
AIエージェントのメモリ統合とは何ですか?
生の会話トランスクリプトを、長期ストレージに書き込まれる構造化された永続的なメモリ(事実、好み、決定事項)に変換するバックグラウンドプロセスです。通常、セッション終了時に強制的なツールコールやJSONモードの補完を通じて実行されます。
チャットをブロックせずに非同期バックグラウンドメモリ統合を実装するには?
チャット応答パスとは別に、セッション終了時やアイドルタイムアウト時にバックグラウンドワーカーのジョブとしてトリガーします。ワーカーは完了時にメモリストアへ書き込みます。ユーザーの次のメッセージはこれを待機しません。これがマルチモデル再試行の遅延を許容可能にする理由でもあります。クリティカルパスの外側で実行されるためです。
5〜7モデルの再試行チェーンは遅延やレート制限の問題を引き起こしますか?
遅延リスクは試行ごとのタイムアウトによって制限され、統合処理を非同期に実行することで吸収されます。レート制限リスクは、チェーンが同じプロバイダーを繰り返し再試行するのではなく、異なるプロバイダー間でフェイルオーバーすることで軽減されます。そのため、あるモデルでの429が別のプロバイダーのクォータを枯渇させることはありません。これらはアーキテクチャ上の緩和策であり、測定された遅延数値ではありません。プロダクション負荷下でこのチェーンをベンチマークしたことはありません。
どのモデルがデフォルトでメモリ統合を処理すべきですか?
DeepSeek V4 Flashのような、ボリュームに対して安価で信頼性の高いモデルから始め、その背後に異なるプロバイダーの4〜5つのモデルを第1層としてチェーンさせます。Claude Sonnet 5とClaude Opus 4.8は、第2層のエスカレーションとしてのみ予約してください。順序を確定する前に、TokenLabモデルディレクトリで現在の価格を確認してください。
フォールバックチェーンのすべてのモデルが失敗した場合はどうなりますか?
破棄するのではなく、生のトランスクリプトを統合せずに永続化し、人間にアラートを出し、トランスクリプト自体(長さ、形式、エンコーディング)がすべてのプロバイダーで失敗を引き起こしていないかを確認してください。7つの独立した障害よりも、共通の原因である可能性が高いためです。
これが実際にコストを削減するかどうかはどうすればわかりますか?
各統合イベントをどの層が解決したかをログに記録し、上記のモデル別価格表を使用して自身のデータからブレンドコストを計算してください。借り物のパーセンテージに頼ってはいけません。解決率はトランスクリプトの長さ、スキーマの厳密さ、プロバイダーの信頼性に依存します。
なぜこの記事には動作するAPIコードが含まれていないのですか?
チェーン内の7つのプロバイダーすべてについて、検証済みの現在のエンドポイント、認証、ペイロード詳細がこの証拠セットに含まれておらず、一見もっともらしいが未検証のリクエストコードを公開することは、コードがないことよりも悪いためです。統合を記述する前に、各プロバイダーの公式APIリファレンスと照らし合わせて上記の検証チェックリストを使用してください。
利用を開始する
コンテキストを静かに失うことが許されないエージェントメモリを構築している場合は、TokenLabの利用を開始してください。現在の価格を比較し、プロバイダーごとに個別の認証情報やレート制限を管理する代わりに、単一のAPIキーを通じてこのフォールバックチェーン内のモデル全体で統合トラフィックをルーティングできます。
出典
価格確認日 2026-07-07
- fal PixVerse V6 model page2026-07-09 時点で確認
- fal FLUX.2 model page2026-07-09 時点で確認
- TokenLab model directory2026-07-07 時点で確認